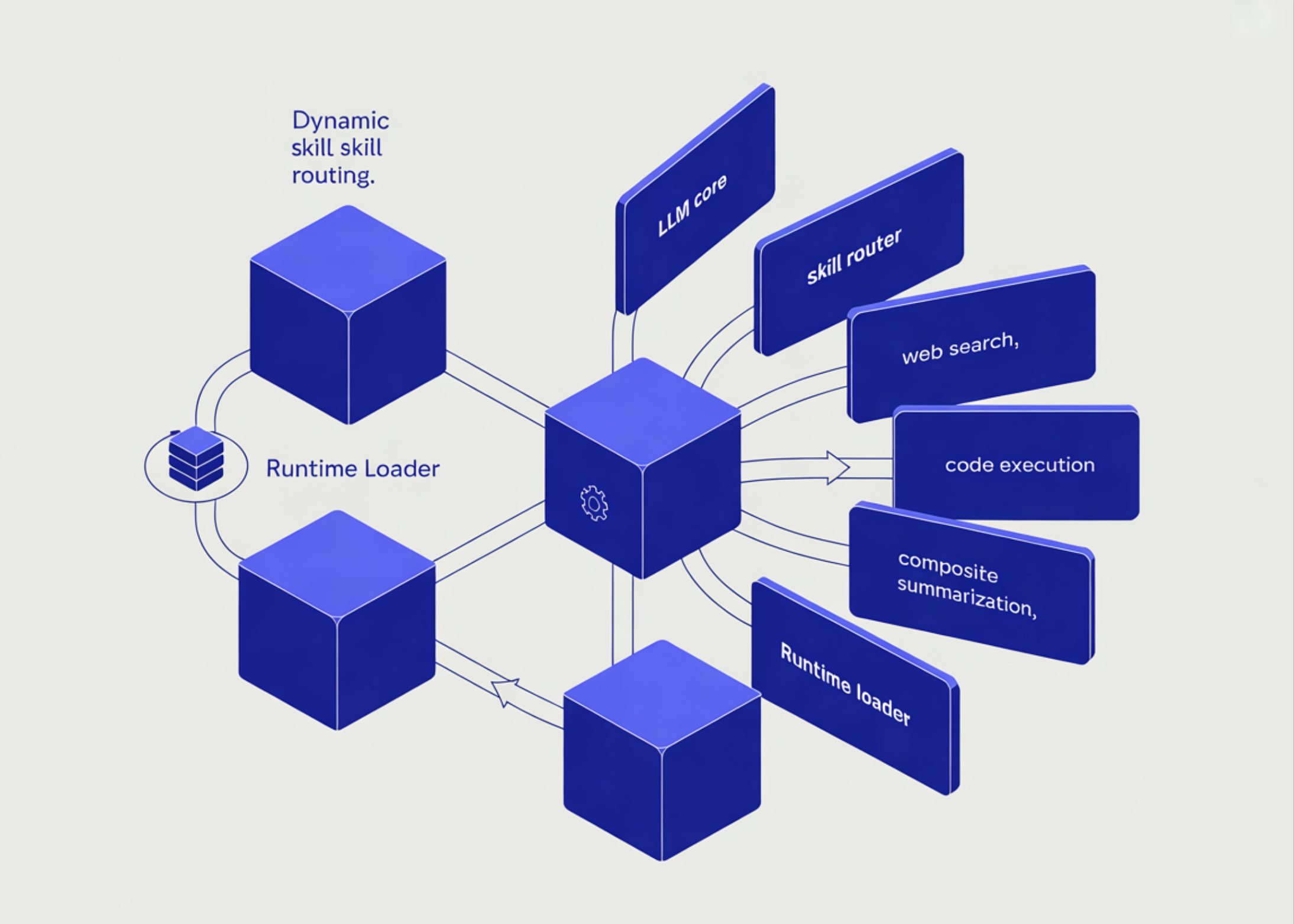
Most AI models today are not designed for continuous, multi-step self-execution. Tasks such as running hundreds of iterative code modifications, or cascading tool calls across hours without human intervention, require a different type of model architecture and training focus.
Alibaba’s Qwen team officially announced Qwen3.7-Max at the 2026 Alibaba Cloud Summit on May 20. Although two preview builds of the Qwen3.7 series have quietly appeared on the Arena AI leaderboard with no press release and no official API announcement.
Two preview models were released simultaneously
Alibaba previewed two models simultaneously: Qwen3.7-Max-Preview and Qwen3.7-Plus-Preview. They are ranked 13th globally in text capabilities and 16th in vision capabilities, respectively, according to LM Arena.
In the Text Arena, Qwen3.7-Max-Preview ranked No. 13 overall, making Alibaba the No. 6 text lab. In the Vision Arena, Qwen3.7-Plus-Preview ranked No. 16 overall, putting Alibaba at No. 5 in the Vision Arena. Model rank and laboratory rank are two separate numbers.
Qwen3.7-Plus-Preview is described as a preview of a balanced, high-performance release, focusing on logical reasoning and expression, with its toolchain gradually opening up in the future. It handles vision and multimodal input. Qwen3.7-Max is the leader in text-only reasoning. This article discusses Qwen3.7-Max, as it is the model officially announced by Alibaba with API access.
What is the design of Qwen3.7-Max?
The Alibaba Qwen team describes Qwen3.7-Max as the most advanced and comprehensive proxy model to date. The model is special and closed weight. It’s capable of handling coding and debugging, office workflow automation, and long-running tasks spanning hundreds or even thousands of steps.
Expanded thinking mode
Qwen3.7-Max is a logic model. The model first generates a series of ideas – an internal sequence of steps where it plans, checks its work, and course-corrects before committing to a final answer. On interfaces like Qwen Chat, this appears as a “thinking” mode that you can turn on to see the model’s logic trace.
Inference models produce a much larger number of output symbols than standard completions. When the artificial analysis performed its IQ evaluation, Qwen3.7-Max generated about 97 million tokens, compared to an average of 24 million for models on this benchmark. For short or simple tasks, this overhead adds latency without improving output quality. For multi-step mapping, code refactoring, or long agent chains, the extended reasoning mode is where the power of the model applies.
Context window
The model features a 1M token context window, compared to 256KB in Qwen3.6 Max Preview. It supports text input and output only. Prices have not been announced yet. The price of Qwen3.6 Max Preview is set at $1.30/$7.80 per million I/O tokens on Alibaba Cloud.
A context window of 1 million tokens can contain an entire medium-sized code repository or a large set of documents in a single request. Models are often less reliable when the context window is full. Long-context independent testing of Qwen3.7-Max is not yet available.
Standard results
The Qwen3.7-Max scored 56.6 on the AI Index, ranking fifth overall. This represents an increase of 4.8 points over its predecessor, the Qwen3.6 Max Preview (51.8), and puts it ahead of the Google Gemini 3.5 Flash (55.3). GPT-5.5 (60.2), Claude Opus 4.7 (57.3), and Gemini 3.1 Pro Preview (57.2) still lead the overall rankings.
IQ Index Version 4.0 collects ten ratings, including GDPVval-AA, Terminal-Bench Hard, SciCode, AA-Omniscience, Humanity’s Last Exam, and GPQA Diamond.

Optimization on Qwen3.6 Max Preview is not uniform. Most of the index’s gains are concentrated in scientific thinking, effective ability, and coding. CritPt rose 9.7 percentage points (from 3.7% to 13.4%), Humanity’s Last Exam jumped 9.2 points (from 28.9% to 38.1%), and Terminal-Bench Hard jumped 6.9 points (from 43.9% to 50.8%). GDP AA added 42 ELO points (from 1504 to 1546). Scores in other benchmarks are largely flat compared to the Qwen3.6 Max Preview.
One of the results in the indicator requires careful reading. In AA-Omniscience, the Qwen3.7-Max’s raw accuracy decreased by 7.6 percentage points (from 37.7% to 30.1%), while the hallucination rate decreased by 21.3 points (from 44.2% to 22.9%). The model chooses to say “I don’t know” more often rather than remember more facts. Its attempt rate dropped from 67.3% to 48.0%, the lowest among the parametric models in the comparison. The AA-Omniscience standard rewards correct answers and punishes hallucinations but there is no penalty for refusing an answer. For use cases that rely on recalling large-scale facts, this is a meaningful constraint to test against your workload.
In Text Arena, Qwen3.7-Max-Preview ranked 13 overall with an Elo score of 1,475. Category rankings include No. 7 in Mathematics, No. 9 in Expert Claims, No. 9 in Software and Information Technology, and No. 10 in Programming.
All indices are preliminary. The model carries a “preview” status, indicating that Alibaba considers it an early build.
Agent performance – internal testing
In an internal Alibaba test on a new chip platform, the model independently made more than 1,000 tool calls and repeated code modifications to optimize a key kernel. Alibaba claimed that the process improved inference speed by about 10-fold compared to the previous version.
Visual explanation of Marktechpost
Key takeaways:
- Alibaba has released two Qwen3.7 preview models: Max (Text/Inference) and Plus (Multimedia).
- The Qwen3.7-Max scored 56.6 on the AI Index, ranking fifth overall – up 4.8 points on the Qwen3.6 Max Preview.
- The 1 million token context window doubles the 256KB limit of Qwen3.6 Max Preview; Text only, no image input.
- In AA-Omniscience, initial accuracy decreased while abstention increased, which is worth testing in knowledge recall use cases.
- The model lasted over 1,000 tool calls and 35 hours of standalone execution in Alibaba internal testing alone; There is no independent verification yet.
verify Technical details. and Documents. Also, feel free to follow us on twitter Don’t forget to join us 150k+ mil SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us