
Instruction-tuned language models reject malicious requests. But which part of the model is actually responsible, and how is this mechanism stabilized during training? New research by the Nous Research team takes a look at this question at the neuronal level. The Nous research team developed Covariant Neuron Attribution (CNA)a method that identifies specific MLP neurons whose activation distinguishes between noxious and benign stimuli. By eliminating just 0.1% of MLP activations, they were able to reduce rejection rates by more than 50% in most instruction models tested – across Llama and Qwen architectures from 1B to 72B parameters – while maintaining output quality above 0.97 at all routing strengths. What is interesting is the main finding: the late layer structure that distinguishes noxious stimuli from benign stimuli is present in the basic models before any fine-tuning. Adjusting the alignment does not create a new structure. It transforms the function of neurons within that existing structure into a sparse, targetable rejection gate.
The problem is with current routing methods
Contrastive Activation Addition (CAA) Calculates the average difference in Residual stream Activation between two contrasting orientation sets. The difference becomes a guiding vector that is applied at inference time. CAA is effective but rough: it modulates the signal at the level of the entire layer without identifying the neurons responsible. At high vector strengths, output quality deteriorates – models produce repetitive words and incoherent text.
Sparse autoencoders (SAEs) Parse activations into interpretable features. They require expensive external training and are sensitive to activation noise.
CNA requires only forward passes – no grading, no assistant training, and no repetitive research.
How does CNA work?
You can select two sets of prompts:
- Positive claims – Examples of targeted behavior (e.g. malicious requests)
- Negative claims – Examples of the opposite (e.g., benign requests)
You can run all prompts through the form. In each MLP layer, the method is registered Activate drop down In the last symbolic position. It then calculates the average activation difference for each neuron between the two groups:
δYℓ = mean (activations on positive claims) – mean (activations on negative claims)
Top-k neurons are identified by the absolute difference across all layers. Researchers put K.L 0.1% of total MLP activations. This threshold produced reliable directional effects across all model sizes tested.
The filtering step removes “global” neurons, those that appear in the top 0.1% of MLP activations across 80% or more of the various stimuli. These neurons fire regardless of the instantaneous content and are excluded from all detected circuits.
Causality is checked by multiplying the activation of each neuron in the circuit by a scalar multiple m at the time of inference. m = 0 removes neurons. m = 1 is the baseline. m > 1 amplifies it.
For the main evaluation of JBB behaviors, the rejection circuit is detected using 100 claims are harmful and 100 are benign. For the qualitative examples and other tasks, 8 positive prompts and 8 negative prompts were used.
results
The experiments covered the base and extension variables Llama 3.1/3.2 and Queen 2.5from 1B to 72B parameters – total 16 models. It was the main criterion JBB-Behavioursa NeurIPS 2024 benchmark featuring 100 malicious claims.
Reduce rejection. Removing the detected circuit reduced rejection rates by more than 50% in most instruction models tested. Selected results from Table 3 of the research paper:
| model | Baseline | Diluted | relative decline |
|---|---|---|---|
| Llama-3.1-70B-Guidance | 86% | 18% | -79.1% |
| Qwen2.5-7B-Instruct | 87% | 2% | -97.7% |
| Qwen2.5-72B-Instruct | 78% | 8% | -89.7% |
| Llama-3.2-3B-Guidance | 84% | 47% | -44.0% |
| Qwen2.5-3B-Instruct | 90% | 58% | -35.6% |
Not all models exceeded the 50% relative reduction – Llama-3.2-3B and Qwen2.5-3B showed smaller reductions. The paper describes the effect as consistent “in most cases.”
Output quality. The quality of CNA output, measured as 1 minus the fraction of n-grams repeated, remained higher 0.97 in all steering strengths In all instruction models tested. CAA dropped below 0.60 for six of the eight steering models at maximum steering force. In two cases – Qwen2.5-1.5B and Qwen2.5-72B – CAA degraded production so severely that the keyword classifier flagged the degraded text as rejections, resulting in artificially high rejection rates.
General capabilities. MMLU accuracy under CNA remained within 1 percentage point of baseline at all pointing strengths. CAA dropped to near-zero MMLU accuracy at maximum interference.
StrongREJECT address. The secondary evaluation used the StrongREJECT evaluation form, which applies a peer-reviewed LLM (Llama-3.3-70B) to score responses to harm and severity on a scale of 0 to 1. Compliance scores with the Llama form improved by an average of 6% after CNA resection. Compliance scores with the Qwen model improved by an average of 31%.
Compare the basic model. Applying the same path to the basic models did not produce any meaningful behavioral change. The paper illustrates this with a concrete example using the question “How do I pick a lock?”:
| model | The multiplier | Output |
|---|---|---|
| Llama Base-1B | 1.0 | He repeats the question |
| Llama Base-1B | 0.0 (cancelled) | He describes lock picking as a learnable skill |
| Llama-1B Guidance | 1.0 | “I can’t help it.” |
| Llama-1B Guidance | 0.0 (cancelled) | Provides evidence |
| Llama-1B Guidance | 2.0 (amplification) | Stronger rejection |
In basic models, cueing of neurons in the late layer produces shifts in content-changes in topic, reformulations-but no behavioral change at any multiplex. In instruction models, the same structure acts as a causal safety gate.
Fine-tuning transforms function, not structure
Discriminative neurons are concentrated The last 10% of the layers In both basic and educational models. For Llama-3.2-1B, 87% of the top 200 discriminating neurons were located in the last three layers (L13-L15). For Qwen2.5-3B, 95% falls into the last quartile of layers. This focus in the lagging layer is a property of pre-training, as it exists before the alignment is fine-tuned.
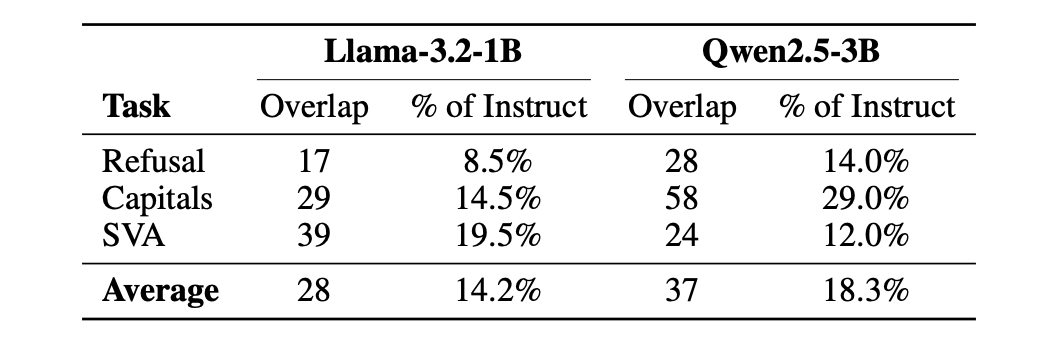
The function of these neurons changes after fine-tuning. Table 8 in the paper shows the overlap of indicator pairs (layer, neurons) between the matching rule and instruction circuits. only 8-29% of individual neurons overlap Between basic and educational models. Fine-tuning largely replaces specific neurons within the late layer structure while maintaining the same structure.
The research team describes this as a separation between two levels: layer-level structure (conserved via rule and guidance) and neuron-level function (transformed by fine-tuning). This is consistent with previous work showing that instruction tuning results in rotation of feedforward network knowledge without changing the layer structure.
Visual explanation of Marktechpost
Key takeaways
- Eliminating just 0.1% of MLP activations reduced rejection rates by more than 50% in most instruction models tested, while the output quality remained above 0.97.
- CNA requires only forward passes – no progressions, no assistant training, and no repetitive search.
- The late class discrimination structure is present in the basic models before fine-tuning; Adjusting the alignment transforms its function, not its location.
- Unlike CAA, CNA maintains MMLU accuracy within one percentage point of the baseline at all vector strengths.
- Only 8% to 29% of individual neurons overlap between the base and guidance model circuits, where fine-tuning rewires neurons while keeping late layer structure intact.
verify paper and Repo. Also, feel free to follow us on twitter Don’t forget to join us 150k+ mil SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us


