
Training and rendering large transformer models at scale is a fundamental problem in memory management. Each GPU in a cluster has a fixed amount of VRAM, and as model sizes and context lengths grow, engineers constantly have to make trade-offs about how to distribute work across devices. A New technology from Zefranamed Tensor and sequence parallelism (TSP), It offers a way to rethink this trade-off – and in benchmark tests on up to 1,024 AMD MI300X GPUs, it consistently delivers less peak memory per GPU than any of the standard parallelism schemes in use today, for both training and inference workloads.
The problem that TSP solves
To understand why TSP is important, you must first understand the two parallelization strategies it brings together.
Tensor Parallelism (TP) Divides model weights across GPUs. If you have a weight matrix in the attention layer or MLP layer, each GPU in the TP cluster only contains a small portion of that matrix. This directly reduces the memory per GPU occupied by parameters, gradients and optimizer states – “model state” memory. The trade-off is that TP requires group communication operations (usually dispersion-minimization or dispersion-minimization/pooling pairs) every time the layer is computed. This connection is proportional to the activation size, so it becomes increasingly expensive as the sequence length grows.

Sequence Parallelism (SP) It takes a different approach. Instead of partitioning the weights, it partitions the input code sequence across GPUs. Each GPU processes only a small fraction of tokens, which reduces the activation memory and quadratic cost of attention computation. However, SP leaves a full copy of the model weights on each GPU, which means that the model’s state memory remains exactly the same no matter how many GPUs you add to the SP pool.
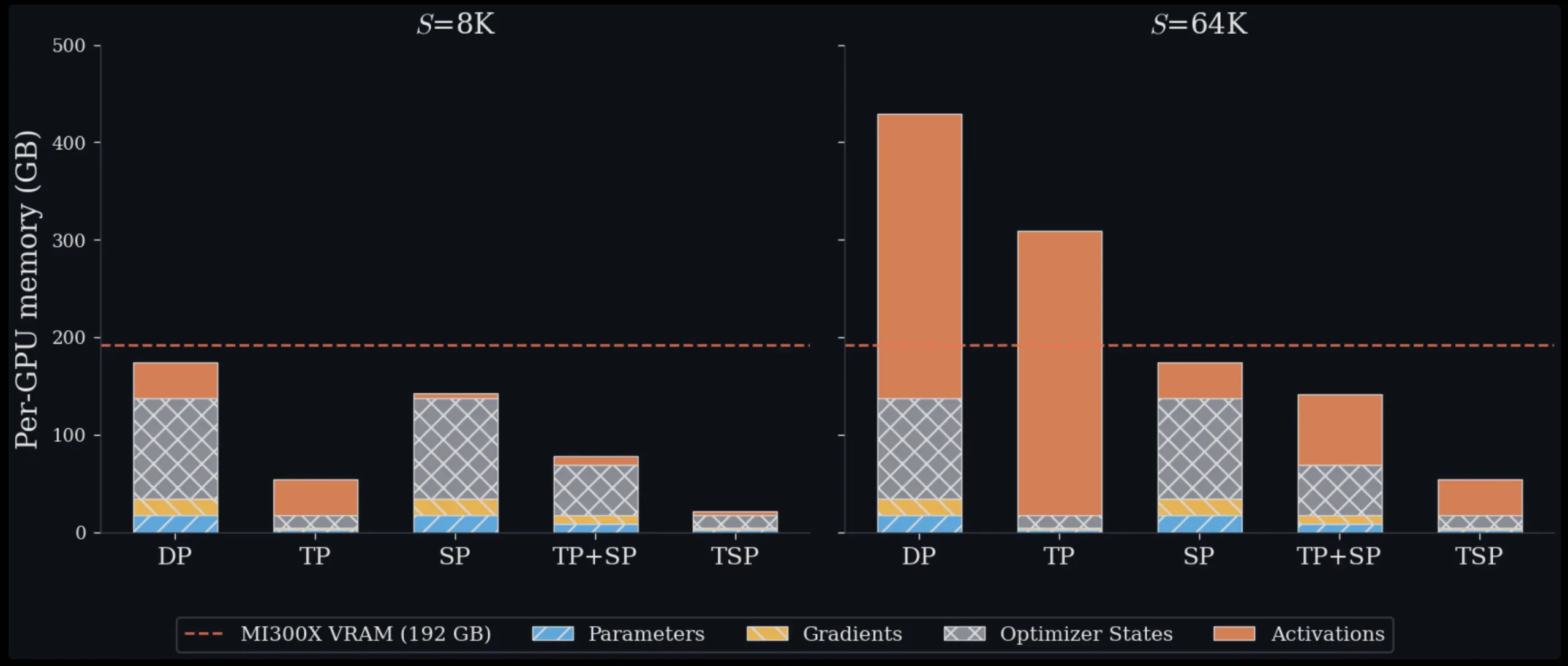
In standard multidimensional parallelism, engineers combine TP and SP by placing them on orthogonal axes to the device grid. If you want a TP score of T and a SP score of Σ, the replica of your model consumes T.Σ GPUs. This is costly in two ways. First, it uses more GPUs for the model’s parallel cluster, leaving fewer available for parallel data replicas. Second, if T.Σ is large enough to include multiple nodes, some group communications must travel over slower internode interconnects such as InfiniBand or Ethernet rather than a higher-bandwidth internal node fabric, such as AMD Infinity Fabric or NVIDIA NVLink. Data parallelism (DP), another common baseline, avoids these model parallel costs altogether but replicates the entire model state on each machine, making it impractical for large models or long contexts alone.
What does folding actually mean?
The basic idea of TSP is parallel convolution: instead of placing TP and SP on separate, orthogonal mesh dimensions, they collapse onto a single device mesh axis of size D. Each GPU in the TSP cluster simultaneously holds 1/D of the model weights and 1/D of the token sequence. Since they are both partitioned across the same D GPUs, the memory footprint per device is reduced by 1/D for both parameter memory and activation memory – something that no standard parallel system achieves on its own. TSP is thus the only scheme that simultaneously minimizes weight-proportional memory (parameters, gradients, optimizer states) and activation memory by the same factor of 1/D on a single axis without requiring a 2D T.Σ device layout.
The challenge is that if each GPU only has part of the weights and part of the sequence, it needs to coordinate with other GPUs to complete the forward pass for each layer. The TSP uses two different communication tables to handle this, one for attention and one for the gated MLP.
To attract attention, the TSP is repeated over the weight fragments. At each step, one GPU broadcasts the packed attention weight parts (WQ, WK, WV, WO) to all other GPUs in the cluster. Each GPU then applies these weights to its local sequence codes to calculate the local Q, K, and V predictions. Since causal attention requires access to the full key/value context, the local K and V tensors are aggregated over the TSP set and rearranged using a zigzag partitioning scheme before applying FlashAttention. The zigzag partition ensures that the causal attention workload is balanced across ranks, since later tokens attend to larger prefixes and may lead to load imbalance.
For a gated MLP, the TSP uses an episode schedule. Each GPU starts with local gate fragments and up- and down-projections. These weight parts orbit the TSP array via point-to-point send/receive operations, and each GPU aggregates the part outputs locally as the parts arrive. Most importantly, this eliminates all the reduction that standard TP requires for MLP output – the sequence stays local, and only the weights move. The ring is designed to overlap weight transfers with GEMM calculations, so that communication occurs in the background while the GPU computes.
Memory and productivity outcomes
Tested on a single 8-GPU MI300X node across sequence lengths ranging from 16K to 128K symbols, TSP achieves the lowest peak memory per node. At 16K symbols, TSP and TP are roughly equivalent, 31.0GB versus 31.5GB per GPU, because model state memory dominates short context. At 128K tokens, the picture changes dramatically: TSP uses 38.8GB per GPU, compared to 70.0GB for TP and 85.0GB and 140.0GB for two different TP+SP workers on the same node. The theoretical numbers in this paper are based on a decoder-only dense transformer reference model of 7B (hidden dimension h = 4096, 32 layers, 32 query heads, 32 KV heads, FFN expansion factor F = 4, bf16 resolution), which provides a repeatable baseline for comparing schemes.
Throughput results on 128 full nodes (1,024 MI300X GPUs) show that TSP consistently outperforms identical TP+SP baselines. At folded degree D = 8 and a sequence length of 128K symbols, TSP achieves 173 million symbols per second compared to 66.30 million symbols per second for the corresponding TP+SP baseline (~2.6x speedup). The advantage grows with higher degree of parallelism and longer sequence length.

Practical trade-offs to understand
TSP increases the total connection size compared to TP alone. It adds a weight motion term to each layer on top of the same activation-proportional K/V set that SP uses. However, the research team showed that when the batch size B and sequence length S satisfy BS > 8h (where h is the model embedding dimension), the forward call size of TSP is competitive with TP. This condition is met in most long-context training and inference scenarios.
The main idea that the Zyphra team emphasizes is that connection volume and connection cost are not the same thing. Whether the additional connection volume translates into wall clock slowdown depends on whether the clusters are latency bound or bandwidth bound, and how much of this traffic can interfere with matrix doubling. Weight moves their execution pipelines behind dominant GEMM processes so that weight communication consumes bandwidth without adding to critical path time.
TSP is not designed to replace TP, SP, or TP+SP in all settings. It is intended to be an additional axis in the multi-dimensional parallel design space. It consists orthogonally of pipeline parallelism, expert parallelism, and data parallelism. This means that teams can introduce TSP into an existing parallel configuration where the standard layout would force parallel clustering of the model via slower links between nodes.
Key takeaways
- Zyphra’s Tensor Parallelism and Sequence Parallelism (TSP) collapses tensor parallelism and serial parallelism onto a single device network axis, such that each GPU simultaneously holds 1/D of model weights and 1/D of token sequence, reducing memory overhead for both training and inference.
- TSP is the only parallelization scheme that reduces both weight-proportional memory (parameters, gradients, optimizer states) and activation memory by the same factor of 1/D on a single axis, without the need for a 2D T.Σ device grid.
- Experimental results on a single 8-GPU MI300X node show that TSP uses 38.8 GB per GPU with a 128 KB serial length, compared to 70.0 GB for TP and 85.0-140.0 GB for TP+SP configurations.
- At scale (1,024 MI300X GPUs, 128K context, D = 8), TSP achieves 173 million symbols per second versus 66.30 million symbols per second for an identical TP+SP baseline (~2.6x throughput advantage).
- TSP consists of orthogonal parallelism of expert and data pipelines and is best suited for long-context, memory-constrained training and inference workloads where weight loss and activation frequency outweigh the additional connection size.
verify paper and Technical details. Also, feel free to follow us on twitter Don’t forget to join us 130k+ ml SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us


