
Web search and content retrieval have become some of the most critical infrastructure decisions in AI agent development. An agent without reliable access to live web data operates effectively on historical knowledge – a strict limitation for any research dealing with production deployment, lead enrichment, competitive intelligence, or real-time monitoring. In 2026, the ecosystem of search and fetch APIs has matured significantly, with purpose-built tools replacing the old style of encapsulating Google SERP metadata and passing it directly into a language model.
This article discusses leading search and fetch APIs based on evaluations across output format, native proxy design, token efficiency, free tier generosity, latency, and framework integrations.
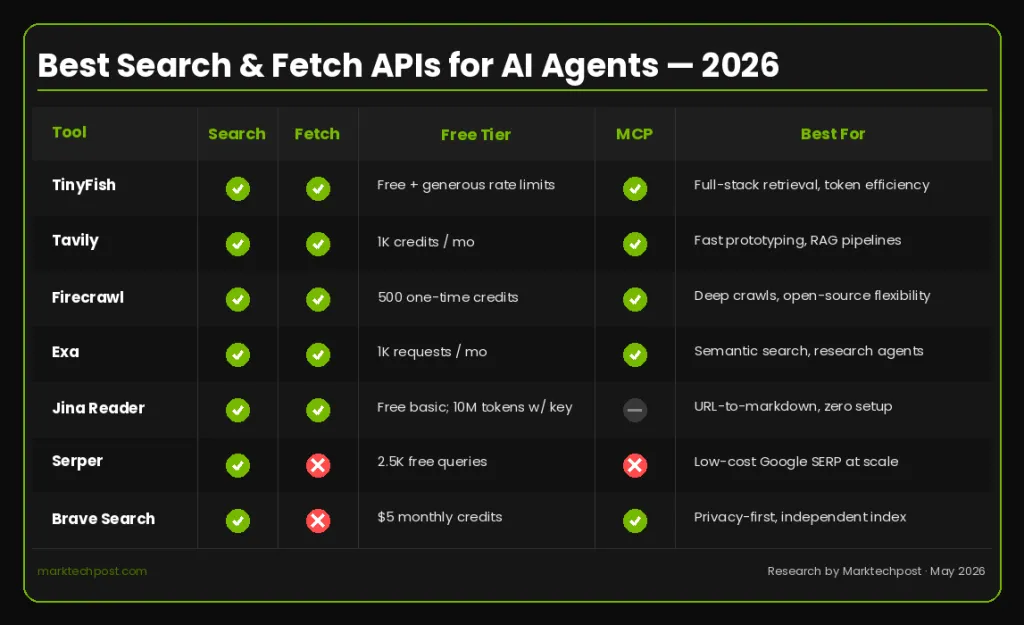
TinyFish
TinyFish is an important participant in this space and among the most direct agents of the group. Its search and fetch endpoints are free with generous pricing caps – one API key, no credit card. The free plan includes searching at a rate of 5 requests per minute and fetching at a rate of 25 requests per minute. The search runs on api.search.tinyfish.ai, returning structured, stable JSON tuned for proxy retrieval rather than human browsing. TinyFish states that the p50 search response time is less than 0.5 seconds – fast enough to sit inside the proxy tools loop without hurting the user experience. Running on api.fetch.tinyfish.ai, Fetch runs a true rendering of the full browser on any URL – including JavaScript-containing SPAs, dynamic content, and anti-bot pages – and returns clean markdown, JSON, or HTML. Failed URLs are free.

The token efficiency angle is the strongest differentiator. Most native fetchers – and the fetchers built into LLM clients – return raw HTML: scripts, navigation, ads, and cookie banners. TinyFish Fetch removes all of that before the content reaches the model, resulting in lower token consumption per page and lower LLM costs per call. The platform runs its own dedicated Chromium fleet end-to-end without middleware, enabling free pricing and production quality. Importantly, these are the same endpoints running production agent workloads – not a degraded experimental layer. The same API key and dashboard are kept when you skip the free plan; No code changes required.
TinyFish is available across all skins that developers are already using. Direct access is via REST API (api.search.tinyfish.ai and api.fetch.tinyfish.ai). MCP support is a JSON configuration dropdown menu for Claude, Cursor, Codex, ChatGPT desktop, or any MCP-aware client. The command line interface (npm install -g @tiny-fish/cli) writes the results directly to the file system rather than passing them through the form context window, keeping token usage low and the output organized. The Agent Skill (npx skills add to github.com/tinyfish-io/tinyfish-cookbook -skill tinyfish) teaches the agent when to call Search vs. Fetch and how to use each – One-line installation, works with Claude Code, Codex, Cursor, OpenCode, and Antigravity. Python and TypeScript SDKs are also available.
Our framework and agent harness integrations include Claude Code, OpenClaw, Hermes Agent (Nous Research), Cline, Cursor, Codex, LangChain, and CrewAI. Platform integrations cover n8n (via the n8n-nodes-tinyfish community node), Dify (the TinyFish Web Agent plugin in the Dify Marketplace), and Vercel Skills. ChatGPT and MCP implementations are also supported.
Taveli
Tavily is a real-time search engine built specifically for AI agents and RAG workflows, providing fast APIs for web search and content extraction. The Researcher plan is free and includes 1,000 API Credits per month, which is enough for prototyping and light evaluation. The paid tiers scale as follows: Enterprise at $30 per month (4,000 credits), Bootstrap at $100 per month (15,000 credits), and Startup at $220 per month (38,000 credits). A pay-as-you-go option is also available at $0.008 per balance with no monthly commitment. Credits reset monthly and do not roll over.
Tavily is known for its deep integrations with LangChain and LlamaIndex and its preprocessing layer that returns ranked and filtered snippets by relevance instead of raw SERP data. One important development to track: Nebius announced an agreement to acquire Tavily in February 2026, which raised questions among some teams about future price stability and roadmap direction when evaluating long-term infrastructure dependencies. Despite this, Tavily remains a fast track from scratch to a working prototype and has extensive integrations within the LLM framework.
Fiery crawl
Firecrawl converts any URL into clean, LLM-ready branding or structured JSON, and is instantly proxy-ready – connects to any MCP client with a single command and supports media parsing of web-hosted PDF and DOCX files along with click, scroll and interact actions before content extraction. It covers four distinct operating modes: Scrape (single markdown URL or JSON), Crawl (recursive scope crawl), Map (URL discovery without fetching content), and Proxy Endpoint for natural language-based data extraction.
The free plan offers 500 one-time credits, enough to test the API and conduct a proof of concept, but not a recurring production allotment. Paid plans start at $16 per month (Hobby, 3,000 credits per month) and extend to $83 per month (Standard, 100,000 credits per month on annual billing). Credits do not roll over from month to month on Standard plans. Firecrawl is open source under AGPL-3.0, which is a useful distinction for teams with data sovereignty requirements. Extensive framework support: LangChain, LlamaIndex, CrewAI, Flowise, and Dify all have native integrations. The MCP server is installed using npx -y firecrawl-mcp and runs across Claude Code, Cursor, Windsurf, and VS Code.
Exa
Exa takes a completely different approach to searching. Instead of keyword matching, it uses neural embeddings to understand the meaning of the query which is why it uses Cursor Exa to power its @web feature. This makes it particularly suitable for research agents, RAG systems where semantic similarity is more important than novelty, and pipelines that need to find conceptually related documents across subject groups rather than the most recent single hit.
The pricing structure for Exa invoices is very simple. Text content and premium features are now included in the search request price with base content for up to 10 results per request, where content extraction was previously billed separately. The free tier offers up to 1,000 orders per month. Content search price is $7 per 1000 requests. Exa ships an official MCP server that supports Claude Desktop, Claude Code, VS Code, Windsurf, and Gemini CLI.
Jenna AI Reader
Jina Reader converts any URL to an LLM-compliant markdown simply by adding https://r.jina.ai/ to the URL, with web search available via https://s.jina.ai/. The Reader API is free for basic use (no API key required). Only a key is needed to unlock the higher price limits, and then fees are applied based on the length of the content rather than per order. New API Keys include 10,000,000 free tokens upon registration. Jina AI now operates within Elastic following the acquisition, and the platform has committed to continuing to develop its Reader, Embeddings, and Reranker APIs.
The usage pattern is very simple: no SDK, no configuration, just URL prefix. But the limitations are real. Jina does not circumvent anti-bot systems and will return an error when blocked. Jina Reader itself is not as deeply integrated into proxy frameworks like LangChain or LangGraph as Tavily, Firecrawl, or Exa, although Jina AI keeps integrations mainly around inlining and reordering products. Its search endpoint (s.jina.ai) fetches the entire top five results instead of returning configurable ordered lists.
Cerber
Serper is one of the most cost-effective options for raw Google SERP data, at $1 per 1,000 queries on the Starter plan and dropping to $0.30 per 1,000 on higher volume plans. New accounts receive 2,500 free inquiries with no credit card required. It returns structured JSON including SERP-specific objects such as knowledge graphs and answer boxes. Serper doesn’t handle content extraction or page fetching – it’s just a search results API. A practical architecture for cost-sensitive pipelines is often a Serper for search combined with a Jina Reader or TinyFish Fetch for content retrieval.
Brave Search API
Brave Search runs on a completely independent index of over 40 billion pages with no affiliation to Google or Bing making it a solid choice for teams with privacy or compliance requirements. Brave uses an independent index and provides strong privacy controls, keeping no data available to enterprise customers. It also ships an official MCP server that supports web search, local business, photos, video, and news.
Recently, Brave removed the free tier for new users, replacing the zero-cost plan with a credit-based billing system. New users get $5 monthly credits – roughly 1,000 inquiries – before their card is charged $5 for every 1,000 inquiries. Existing users on the old free plan are migrated and retain their prior access. Brave does not provide an endpoint for content extraction or fetching – it is a search-only provider, and is best suited for deployments where index independence and privacy controls are challenging requirements.
Key takeaways
- TinyFish is the overall winner in both fetch and search. It’s a powerful, all-in-one retrieval option for developers who need search, fetch, and native agent integrations within a single platform, with the free tier providing an initial 500 credits for evaluating both endpoints in a real workflow.
- Tavily remains a fast track to a production-level agent and has the deepest LLM framework integrations in the category, although its credit levels are compressing the prime space broadly.
- Exa is very powerful in the area of semantic retrieval and encoding agent searching, where keyword engines miss results from neural matching surfaces.
- Firecrawl can be a good choice for crawl-intensive extraction workflows and teams that want an open source foundation they can self-host.
- Jina Reader is the lowest friction URL option for markdown, requiring nothing more than a URL prefix to get started.
- Serper is cost effective relative to Google SERP data by volume.
- Brave is a solid choice for standalone indexing for privacy-sensitive deployments, and now comes with an official MCP server.
Feel free to follow us twitter Don’t forget to join us 130k+ ml SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us


