Poetiq has just published some interesting results showing that its metasystem has reached the state-of-the-art in LiveCodeBench Pro (LCB Pro), a competitive coding standard, by automatically building and optimizing its inference tool – without tuning any underlying model or accessing the internals of the model.
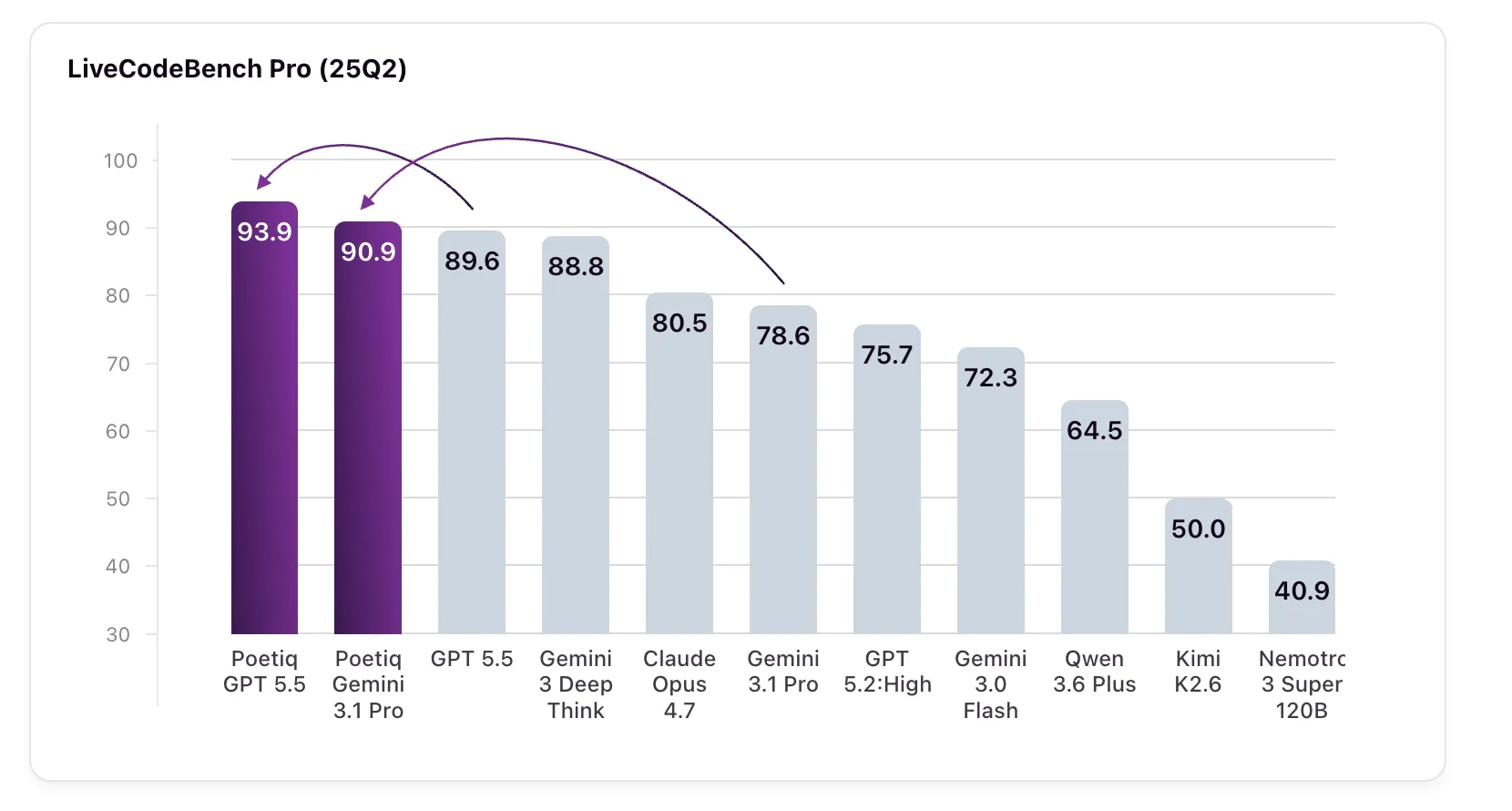
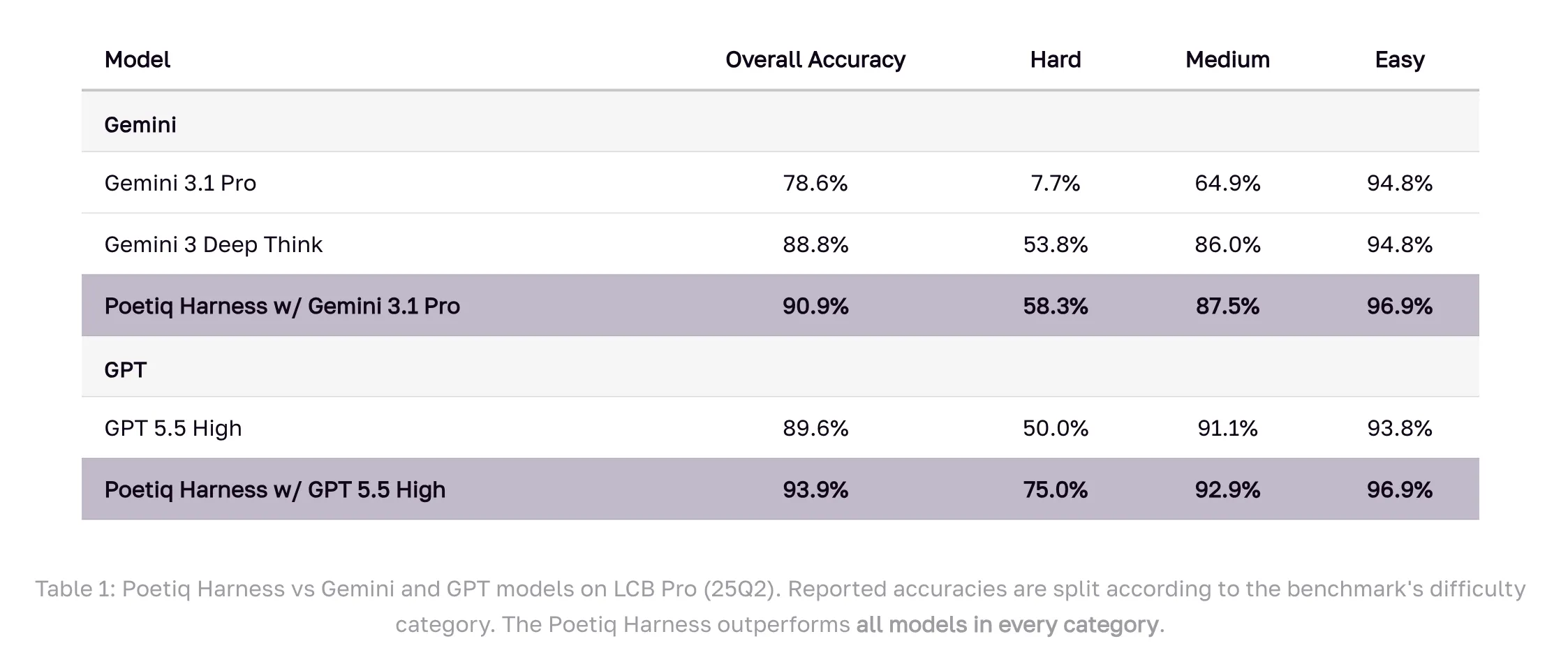
Result: GPT 5.5 High with the Poetiq suite achieving 93.9% on LCB Pro (25Q2), up from a baseline of 89.6%. Gemini 3.1 Pro, the model on which the band was specially optimized, jumps from 78.6% to 90.9% – surpassing Google’s own Gemini 3 Deep Think (88.8%), a model that is not even accessible via an external verification API.
What is LiveCodeBench Pro?
Before getting into the mechanics, it’s helpful to understand why the standard is important. LiveCodeBench Pro (LCB) is designed to test AI coding ability in a way that resists two failure modes common in standards: data contamination and overcomposition.
LCB Pro pulls problems from major competitive programming contests and obscures generic ground truth code. Instead, solutions are validated against a comprehensive testing framework. Correct output alone is not enough – solutions must also meet certain memory and runtime constraints. The standard is also subject to constant updates, which sets it apart from many standards that have become outdated.
The standard focuses on C++ challenges and emphasizes creative programming, testing a model’s ability to solve complex problems and high-quality procedural logic and performance. This sets it apart from datasets like SWEBench that evaluate tool usage or bug fix workflows. Problems are ranked by difficulty – easy, medium and hard – based on competitive human solution rates.
Poetiq’s Strategic Framework: Three Categories of LLM Tasks
This is Poetiq’s third publicly announced benchmark, and the choice of LCB Pro was deliberate. The research team frames LLM performance around three distinct task categories: inference challenges (ARC-AGI is their standard here), retrieval challenges (Humanity’s Last Test, or HLE), and programming challenges-which, as the most widespread commercial application of AI today, mix inference and retrieval with the generation of specialized procedural logic.
Their coding initiative had three specific, stated goals: first, to prove that a smart belt could enhance efficiency without fine-tuning or access to a proprietary model; Second, verify the ability of the meta-system to iteratively self-improvement in automatically generating this belt; Third, we prove that the resulting belt is model-neutral and can be applied to any model without modification. According to their results, all three were satisfied.
What is a belt and why is it important?
In this context, a belt refers to the infrastructure wrapped around a language model to handle a specific task. Think of it as an orchestration layer-it controls how the form is prompted, how the output is organized, how answers are aggregated across multiple calls, and how solutions are evaluated.
Traditionally, these saddles are handcrafted by engineers. Poetiq claims that its induction system builds and improves these tools automatically, through iterative self-improvement. Internally, the declarative system works by developing better strategies for deciding what to ask, refining the sequence of questions, and devising new ways to group answers. The system continually integrates lessons learned from past and existing missions and data sets to create new, customized mission-specific tools – as well as agents and orchestrators for other mission types.
How was the belt built??
Poetiq’s Meta-System was tasked with the LCB Pro and the harness was built from scratch using only the Gemini 3.1 Pro as the base model. The meta-system takes into account all three dimensions of LCB Pro tests: accuracy, runtime, and memory limitations. The system drew on insights from its previous work on ARC-AGI and HLE when designing the belt. No fine-tuning was done to the underlying model, and no access to internal model activations was needed – just standard API access.
Once the belt was created and optimized for the Gemini 3.1 Pro, it was then applied to a wide range of other models from different providers and generations – both open and proprietary – without any further optimization. Every model tested has been improved.
Numbers
The benchmark results across difficulty levels are worth looking at in detail. On the hard problems-the category where the gaps between models are largest-the Gemini 3.1 Pro with the Poetiq band achieved 58.3%, up from a baseline of 7.7%. GPT 5.5 High with the belt reaches 75.0% on the hard drive, up from 50.0%. Across the easy and medium categories, the saddle also outperforms all basic models.
Some results from smaller models are also notable. Gemini 3.0 Flash improved by 10 percentage points, rising from 72.3% to 82.3%, beating the Cloud Opus 4.7, Gemini 3.1 Pro, and GPT 5.2 High, all of which are larger and more expensive models. This mirrors a pattern that Poetiq had previously observed on ARC-AGI, where their improvement allowed a smaller, more economical model to outperform a larger model. Kimi K2.6 sees the largest jump: from 50.0% to 79.9%, an improvement of about 30 percentage points. Nemotron 3 Super 120B improved by 12.8%.
Accuracy numbers are reported directly from the LCB Pro leaderboard on Livecodebenchpro.com (25Q2). For models not included in the leaderboard, Poetiq conducted its own evaluations, validating its experimental setup by replicating the accuracy of the official leaderboard for the base models.
Key takeaways
- Poetiq’s Meta-System automatically builds task-specific tools through iterative self-improvement, without the need for model tuning or access to the internal model
- GPT 5.5 High with the belt hitting 93.9% on the LCB Pro (25Q2), up 4.3% from the baseline of 89.6%; Gemini 3.1 Pro jumps 12.3% (78.6% → 90.9%)
- The belt is model-independent: optimized with the Gemini 3.1 Pro only, it has improved all other models tested – open and proprietary weights – without modification.
- The Gemini 3.0 Flash gains 10 percentage points with the belt (72.3% → 82.3%), beating the Claude Opus 4.7, Gemini 3.1 Pro and GPT 5.2 High despite being smaller and cheaper.
- Kimi K2.6 shows the largest gain at approximately 30 percentage points (50.0% → 79.9%); Nemotron 3 Super 120B improved by 12.8%
verify Technical details here. Also, feel free to follow us on twitter Don’t forget to join us 150k+ mil SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us