If you’ve been running reinforcement learning (RL) after training a language model for mathematical reasoning, code generation, or any verifiable task, you’ve almost certainly stared at the progress bar while your GPU cluster burns through subtractive generation. A team of researchers from NVIDIA proposes an exact solution by incorporating speculative decoding into the RL training loop itself, and doing so in a way that preserves the exact distribution of the target model’s outputs.
The research team integrated speculative decoding directly into Nemo RL v0.6.0 With a vLLM backend, providing lossless subtraction acceleration at both 8B and 235B projected scales. The latest NeMo RL v0.6.0 officially ships speculative decoding as a supported feature alongside the SGLang backend, the Muon optimizer, and YaRN long-context training.
Why is offering creation a bottleneck?
To understand the problem, it is useful to know how the concurrent RL training step breaks down. In NeMo RL, each step consists of: Five stages: data loading, weight synchronization and backend setup (setup), proposition generation (generation), log likelihood recalculation (logprob), policy optimization (training).

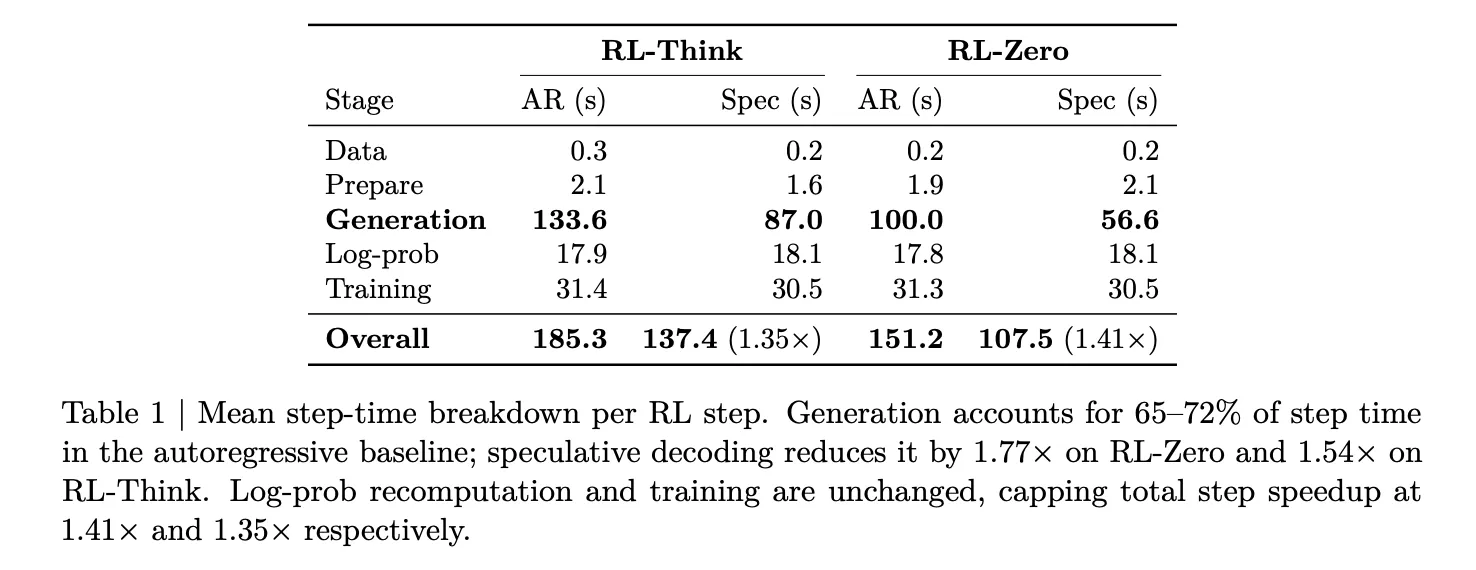
The research team measured this collapse on Qwen3-8B below Two workloads – RL-Thinkwhich continues to train a model capable of thinking, and RL-zeroWhich starts from the basic model and learns to think from scratch. In both cases, generating the subtraction represents 65-72% of the total step time. Recalculating the log likelihood and training together only takes about 27-33%. This makes the generation process the only phase worth targeting for acceleration, and the phase that sets the maximum limit for any improvement on the launch side.
What does speculative decoding actually do?
Speculative decoding is a smaller and faster method Draft model Several symbols are suggested at once, the larger Goal model (which you are already training) checks them using a rejection sampling procedure. The key property and why it is important for RL is that the rejection procedure is mathematically guaranteed to produce the same distribution of outputs as if the target model had generated those tokens regression-wise. There are no mismatches in the distribution, no need for out-of-policy corrections, and no change in the training signal.
This is important because in the post-training phase of RL, the training reward depends on the private policy samples. Methods such as asynchronous execution, out-of-policy replay, or low-precision rollouts all trade some accuracy in training for throughput. Nothing is traded off in speculative decoding: the primings are identical in distribution to what the target model would have generated on its own, but they are produced faster.
System integration challenge
Adding a draft form to your presentation backend is simple. Adding one to the RL training loop is not. Every time the policy is updated, the subtraction engine must receive new weights. The draft model must remain consistent with evolving policy. The log odds, KL penalties and GRPO policy loss must be calculated according to the target (verifier) policy and not the draft or the optimization target is silently corrupted.
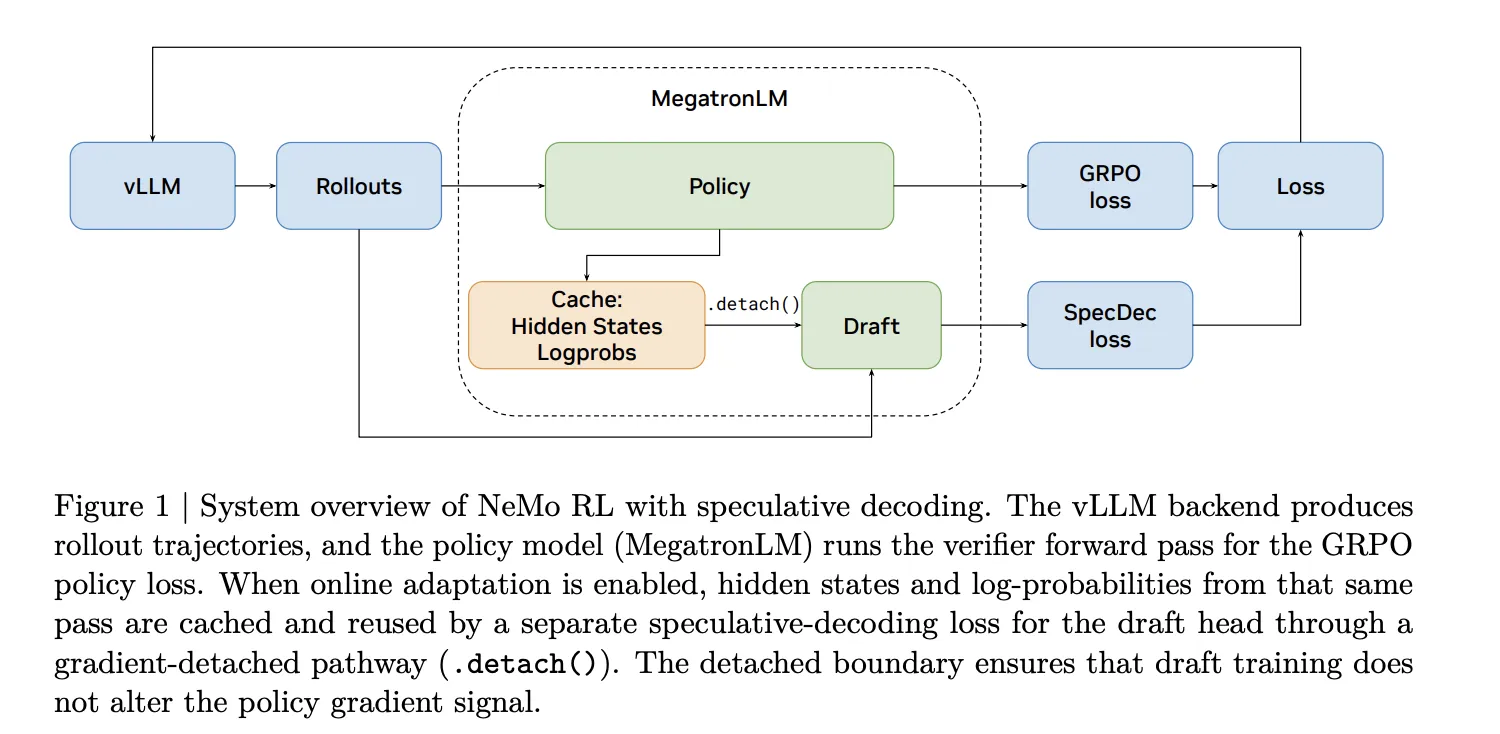
The NVIDIA research team addresses this in NeMo RL using a Two-track architecture. The general pipeline uses EAGLE-3, a formulation framework that works with any pre-trained model without the need for native multi-code prediction (MTP) support. Native pathing is also available for models that come with built-in MTP headers. When online draft modification is enabled, the hidden states and log probabilities from the MegatronLM verifier’s forward pass are stored and reused to supervise the draft head via a separate gradient path, so draft training never overlaps with the policy gradient signal.
Results measured on the 8B scale
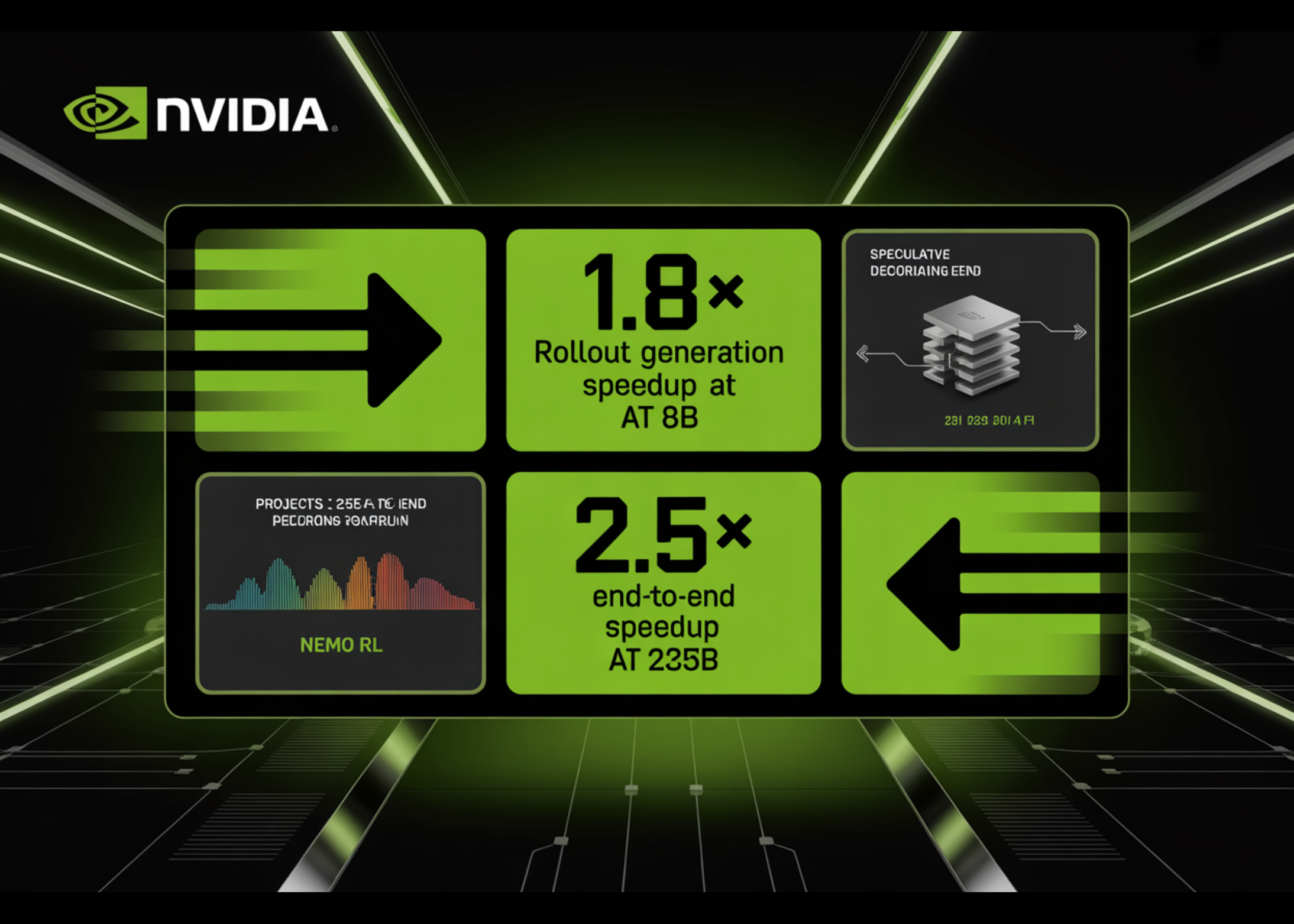
On 32 GB200 GPUs (8 GB200 NVL72 nodes, 4 GPUs per node), EAGLE-3 reduces generation latency from 100 seconds to 56.6 seconds on RL-Zero – a 1.8x generation speedup. In RL-Think, it dropped from 133.6 seconds to 87.0 seconds, a speedup of 1.54x. Since log-likelihood recalculation and training are unchanged, these generation gains translate into an overall step speedup of 1.41× on RL-Zero and 1.35× on RL-Think. The validation accuracy of AIME-2024 evolves similarly under automatic and speculative decoding throughout training, confirming that the lossless guarantee holds in practice.
The research team is also testing the n-gram formulation as a model-free speculative baseline. Despite achieving acceptance lengths of 2.47 on RL-Zero and 2.05 on RL-Think, n-gram formulation is slower than the autoregressive baseline on both settings – 0.7× and 0.5× respectively. This is a critical finding for practitioners: the length of positive acceptance is necessary but not sufficient. If verification costs are high enough, speculation makes matters worse.
Three configuration decisions determine the speed achieved
The research team isolated Three operational options Practitioners should get it right.
Preparation project It matters more than general drafting ability. The EAGLE-3 draft initialized on the DAPO post-training dataset achieves a 1.77× speedup on RL-Zero, while the draft initialized on the general-purpose UltraChat and Magpie datasets achieves only 1.51× with the same draft length. The draft should be in line with the actual rollout distribution encountered during RL, not just a large-scale chat distribution.
Draft length It has an unclear optimum. At draft length k = 3, RL-Zero achieves 1.77× speedup and RL-Think achieves 1.53× speedup. Increasing to k=5 raises the acceptance length but drops the speed to 1.44× on RL-Zero and 0.84× on RL-Think – the latter already slower than autoregressive. At k=7, RL-Zero drops to 1.21× and RL-Think to 0.71×. Variance matters: RL-Zero rolls are generated from a basic model that starts with short outputs, making them easier for the draft to predict even at high k. It is difficult to predict the effects of fully developed heuristics for RL-Think, so the overhead of longer drafts erases the benefit sooner. More reflective work at each step can completely erase the benefit of higher acceptance, especially in more difficult generation systems.
Online adaptation project – Updating the draft during RL using rollouts generated by the current policy helps a lot when the draft is poorly initialized. For a configured DAPO draft, offline and online configurations perform almost identically (1.77x vs. 1.78x on RL-Zero). For a draft configured with UltraChat, the online update improves speed from 1.51x to 1.63x on RL-Zero.
Interact with asynchronous execution It has also been tested directly on the 8B scale and not just in simulation. The research team ran RL-Think at Policy Lag 1 in a 16-node asynchronous configuration, with 12 nodes dedicated to generation and 4 nodes to training. In asynchronous mode, most of the rollout generation is already hidden behind log probability recalculations and policy updates, so the relevant amount is exposed generation time that remains on the critical path. Speculative decoding reduces the exposed generation time from 10.4 s to 0.6 s per step and reduces the effective step time from 75.0 s to 60.5 s (1.24×). The gain is smaller than in synchronous RL-which is to be expected, since asynchronous interference already hides much of the rollout cost-but it confirms that the two mechanisms are truly complementary and not redundant.
Expected gains at 235B scale
Using a proprietary GPU performance simulator calibrated to device-level compute, memory, and interconnect characteristics, the research team predicted speculative decoding gains at larger scales. For the Qwen3-235B-A22B running synchronous RL on 512 GB200 GPUs, draft length k = 3 with an accept length of 3 symbols results in a 2.72× rollout speedup and a 1.70× end-to-end speedup.
At the most suitable emulated operating point – Qwen3-235B-A22B on 2048 GB200 GPUs with asynchronous RL at policy delay 2 – the rollout speedup reaches approximately 3.5x, which translates to an expected 2.5x end-to-end training speedup. Speculative decoding and asynchronous execution are described as complementary: speculative decoding minimizes the cost of each individual firing, while asynchronous interleaving hides the remaining generation time behind training and log-likelihood calculation.
Key takeaways
- Proposition generation is the prevailing bottleneck in the post-training phase of RLaccounting for 65-72% of the total stride time in concurrent RL workloads – making it the only phase where acceleration has an appreciable effect on overall training speed.
- Speculative decoding via EAGLE-3 provides lossless subtraction accelerationachieving a 1.8× generation speedup at 8B scale (1.41× total step speedup) without changing the distribution of the target model’s output – unlike asynchronous execution, out-of-policy restarts, or low-precision rollouts, all of which trade training accuracy for throughput.
- The quality of the draft format is more important than the length of the draftwith in-domain drafts (trained by DAPO) outperforming public chat domain drafts by a large margin; Longer draft lengths (k≥5) consistently backfire on harder inference workloads, making k=3 the reliable default.
- Simulation projections show a significant increase in gainsup to ~3.5x subtraction speedup and ~2.5x expected end-to-end training speedup at 235B scale on 2048GB GPUs – this technology is already available in NeMo RL v0.6.0 under Apache 2.0.
verify Full paper and Nemo RL Repo. Also, feel free to follow us on twitter Don’t forget to join us 130k+ ml SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us

