As LLM-powered applications move into production – and as AI agents take on more critical tasks like browsing the web, writing and executing code, and interacting with external services – security oversight has quietly become one of the most operationally expensive parts of the stack.
Most developers who have deployed a production LLM system know the problem: you need to evaluate every user prompt before it reaches the form, and every form response before it reaches the user. This means your guardrail model works on every request, at every turn in the conversation. Cummins handrail compounds. Cost vehicles. The current generation of open source guardrail models – LlamaGuard4 (12B), WildGuard (7B), ShieldGemma (27B), and NemoGuard (8B) – are all decoder-only models with billions of parameters, and are designed for flexibility but not speed.
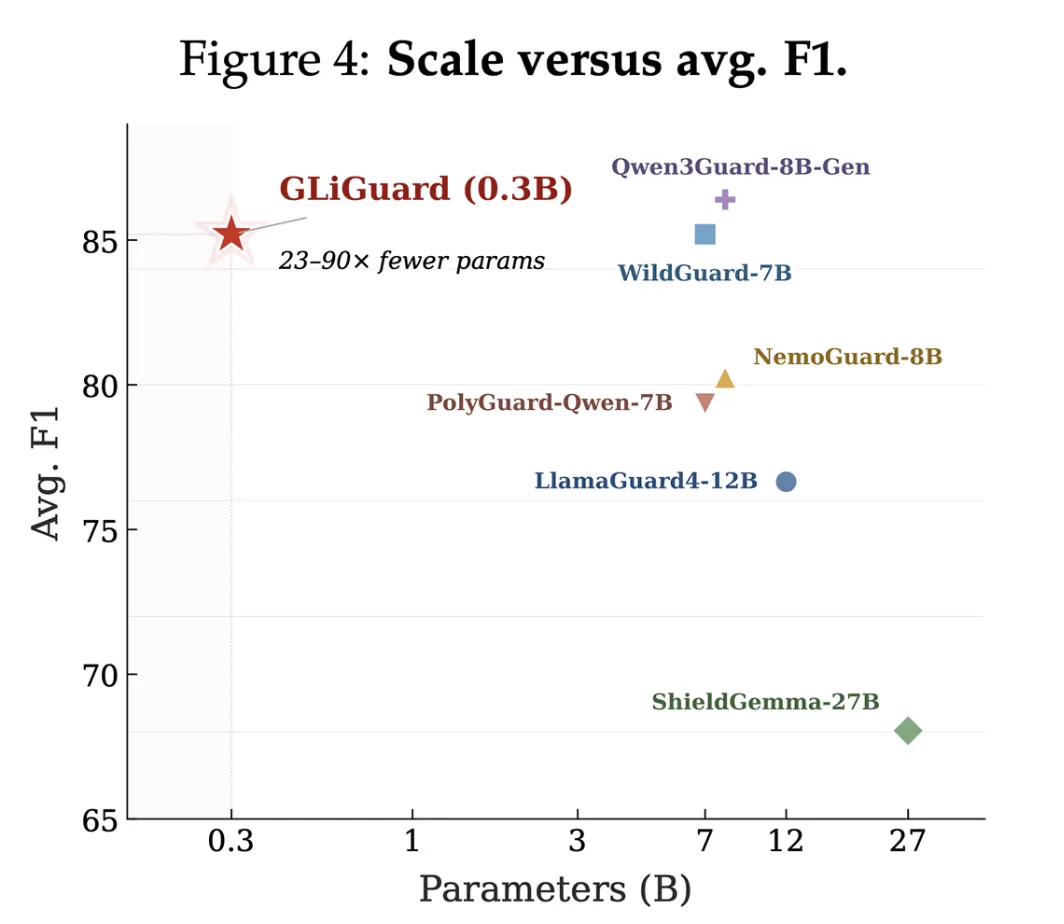
Fastino Labs has released GLiGuard, an open source security monitoring model with 300 million parameters designed to address exactly this problem. GLiGuard evaluates multiple safety dimensions in a single pass, and across nine safety criteria, its accuracy matches or exceeds models 23 to 90 times its size while operating up to 16 times faster.
To understand what makes GLiGuard different, it helps to understand why current guardrail models are so slow. Most major guardrail models are built on decoder-only switch architectures, and they generate their integrity judgments water-wise, one symbol at a time – in the same way that a large language model generates a response to a conversational message.
This design made sense when safety requirements were fluid. Decoder models can interpret natural language task descriptions and adapt to new safety policies without retraining. But generating autoregressive is sequential in nature, which makes it slow and computationally expensive.
There is a compound problem on top of that. Most guardrail models need to evaluate inputs across multiple safety dimensions: what kind of damage is present, whether the user prompt is trying to bypass safety training, whether the model’s response is itself unsafe, and so on. Since decoder models generate outputs sequentially, these evaluations are typically produced one at a time, and latency components are evaluated with further criteria.
In other words, the structure that makes decoder models flexible is also the structure that makes them the wrong tool for what is essentially a classification problem.
What GLiGuard actually does
GLiGuard is a small encoder-based model that reformulates secure supervision as a text classification problem rather than a text generation problem. Encoder models process the entire input at once and output a single classification label for a set of fixed labels, while decoder models generate their output one token at a time, from left to right.
The key architectural insight is how GLiGuard handles multiple tasks simultaneously. Instead of creating tokens, GLiGuard encrypts both the input text and task definitions (labels) together. These are then fed into the model, which scores each mark simultaneously in a single forward pass and returns the mark with the highest score for each task. Since all tasks and their candidate labels are part of the same input, evaluating additional security dimensions does not add latency; It simply means including more labels in the entry.

GLiGuard runs four supervision tasks simultaneously in a single forward pass:
- Safety rating (Secure/Not Secure) – Applies to both pre-creation user prompts and post-creation form responses.
- Uncover your prison escape strategy Across 11 strategies, including immediate injection, role-playing bypass, instruction bypass, and social engineering. If any jailbreak strategy is detected, the claim will be automatically marked as unsafe.
- Damage class detection Across 14 categories – violence, sexual content, hate speech, exposure of PII, misinformation, child safety, copyright infringement, and others. A single entry can trigger multiple classes at once.
- Rejection detection (Compliance/Rejection), tracked separately to help measure excessive rejection (when the model rejects secure requests) and false compliance detection (when the model appears to be complying but isn’t). If a rejection is detected, the response is automatically marked as secure.
Training data and fine-tuning
GLiGuard is trained on a combination of human-annotated and synthetically generated training data. For rapid safety, response safety, and denial detection, the team used WildGuardTrain, a dataset of 87,000 human-annotated examples. For damage class and jailbreak strategy detection, labels for insecure samples were generated using GPT-4.1.
During early training, the model struggled to differentiate between similar harm categories such as toxic speech and violence, so the team used Pioneer to create supplemental synthetic data with fringe cases targeting these nuances.
On the architectural side, GLiGuard was trained by fully fine-tuning the GLiNER2-base-v1 checkpoint for 20 epochs using the AdamW optimizer. GLiNER2 is Fastino’s proprietary architecture for multi-task text classification – a natural starting point for a model designed to capture multiple label sets in a single pass.

Standard results: accuracy and speed
The research team evaluated GLiGuard across nine consistent safety criteria. These criteria cover both fast and responsive rating, testing whether the model can identify malicious content, resist adversarial attacks, differentiate between different types of damage, and avoid over-flagging safe content. The results use the overall mean F1, which is a standard metric that balances precision and recall.
On accuracy:
- The GLiGuard scored an 87.7 F1 average in the spot rating, within 1.7 points of the best model (PolyGuard-Qwen at 89.4).
- It achieved the second-highest average F1 response rating (82.7), behind only the Qwen3Guard-8B (84.1).
- It outperforms LlamaGuard4-12B, ShieldGemma-27B, and NemoGuard-8B despite being 23-90× smaller.

Regarding throughput and latency, measured on a single NVIDIA A100 GPU:
- GLiGuard achieves up to 16.2× higher throughput (133 vs. 8.2 samples/s at batch size 4).
- GLiGuard achieves 16.6×:26 ms lower latency versus 426 ms at sequence length 64.
These are not marginal improvements. At 26 ms per request versus 426 ms, the difference is meaningful in any real-time user-facing application, and the compounding effect across a multi-turn conversation makes the gap even larger in practice.
Visual explanation of Marktechpost
Key takeaways
- GLiGuard is a security supervision model based on the 300M encryption tool that handles four tasks – security classification, jailbreak detection, damage classification, and denial detection – in a single forward pass.
- Unlike decoder-only guardrail models that generate judgments retrospectively, GLiGuard reformulates secure supervision as a text classification problem, eliminating the sequential latency bottleneck.
- GLiGuard has been benchmarked on a single NVIDIA A100 GPU, and achieves up to 16.2x higher throughput and 16.6x lower latency (26ms vs. 426ms) compared to current SOTA models like the ShieldGemma-27B.
- Across nine safety measures, GLiGuard scored an F1 average of 87.7 in the Immediate rating and 82.7 in the Response rating – outperforming the LlamaGuard4-12B, ShieldGemma-27B and NemoGuard-8B despite being 23-90× smaller.
- Model weights under Apache 2.0 are available on Hugging Face (
fastino/gliguard-LLMGuardrails-300M), making it deployable on a single GPU without heavy infrastructure.
verify paper, Typical weights at high frequency, GitHub repo and Technical details. Also, feel free to follow us on twitter Don’t forget to join us 150k+ mil SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us