
The fundamental tension in conversational AI has always been a binary choice: rapid response or intelligent response. Real-time speech-to-speech (S2S) models-the kind that support natural-feeling voice assistants-start speaking almost immediately, but their answers tend to be shallow. Cascade systems that route speech through a large language model (LLM) are much more familiar, but the pipeline delay is long enough to make conversation sound stilted and robotic. Researchers at Sakana AI, The Tokyo-based Artificial Intelligence Lab offers… Cami (an extension of the Knowledge Access Model), a hybrid architecture that maintains near-zero latency for the live S2S system while pumping richer knowledge to the back-end MBA in real time.
The problem: two models, two trade-offs
To understand why KAME is important, it is helpful to understand the two dominant designs that the bridge connects.
A direct S2S model like Moshi (developed by KyutAI) is a homomorphic converter that takes phonetic tokens and produces phonetic tokens in a continuous loop. Because it doesn’t need to sync with external systems, response latency is exceptionally low – for many queries, the form starts speaking even before the user finishes their question. But because audio signals are more information dense than text, the model must expend a significant amount of power modeling paralinguistic features such as tone, emotion, and rhythm. This leaves less room for factual knowledge and deep thinking.

In contrast, a cascade system routes the user’s speech through an automatic speech recognition (ASR) model, feeds the resulting text into a powerful LLM, and then converts the LLM response back into speech via a text-to-speech (TTS) engine. The quality of knowledge is excellent – you can connect any borderline LLM – but the system must wait until the user has finished speaking before ASR and LLM processing begins. The result is an average latency of about 2.1 seconds, which is long enough to significantly interrupt the normal flow of conversation.
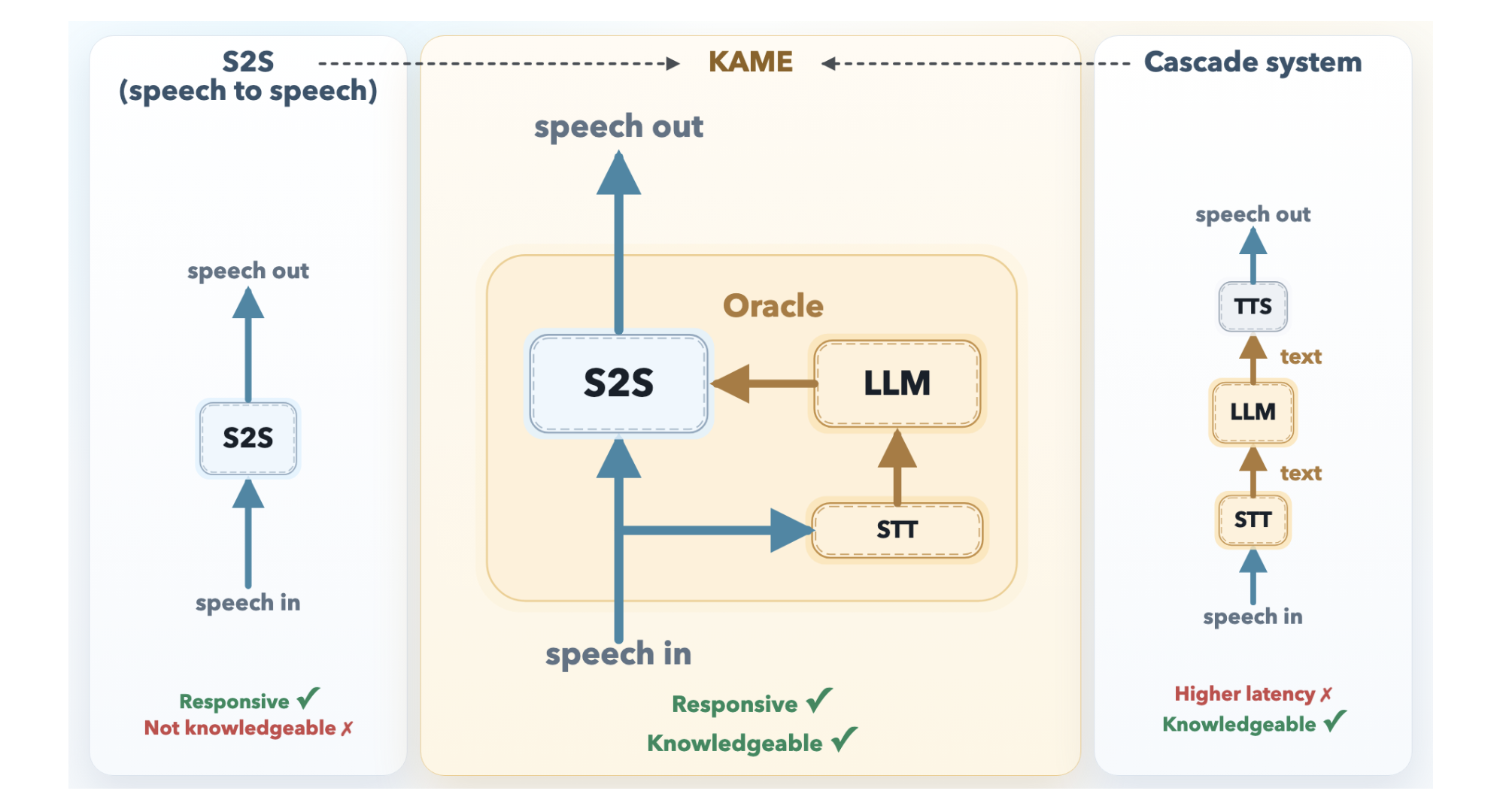
Kami Structure: Speaking while thinking
KAME operates as a tandem system containing two asynchronous components running in parallel.
the S2S front unit It is based on the Moshi architecture and processes audio in real time in a discrete audio symbol cycle (about every 80 milliseconds). It begins generating a spoken response immediately. Internally, Moshi’s original three-stream design-input audio, internal monologue (text), and audio output-has been expanded in KAME with a fourth stream: Oracle stream. This is the main innovation point.
the LLM rear module It consists of a speech-to-text (STT) component combined with a broad-based LLM. When the user speaks, the STT component constantly generates partial text and periodically sends it to the back-end LLM. For each partial copy it receives, LLM creates a filtered text response – called an oracle – and flows it back to the front end. As the user’s speech continues to arrive, these prophecies start out as educated guesses and become progressively more accurate as the text is completed.
The front-end S2S adapter then adapts its continuous speech output to both its own internal context and the incoming oracle tokens. When a new, better revelation arrives, the model can course-correct, effectively updating its response mid-sentence, in the same way a human might. Since both units operate asynchronously and independently, the initial response time remains close to zero.
Oracle simulation training
One challenge is that there is no natural dataset that contains oracle signals. The Sakana AI research team addresses this with a technology called Oracle Boost Simulation. Using an LLM “simulator” and a standard conversation dataset (user speech + ground truth response), the research team creates synthetic oracle sequences that mimic what LLM can produce in real time across different levels of text completeness. It defines six cue levels (0-5), ranging from a completely unguided guess at cue level 0 to a literal ground truth response at cue level 5. Training data for KAME was generated from 56,582 synthetic dialogues taken from MMLU-Pro, GSM8K, and HSSBench, converted to audio via TTS and augmented with these progressive oracle sequences.
Results: almost sequential quality, and near-zero latency
Evaluations on a subset of synthesized speech for the MT-Bench multi-turn question-and-answer benchmark – specifically the Reasoning, STEM, and Humanities categories (encoding, extraction, mathematics, role-playing, and writing were excluded as unsuitable for speech interaction) – show significant improvement. Moshi alone scores 2.05 on average. KAME with gpt-4.1 back-end scored 6.43, and KAME with claude-opus-4-1 back-end scored 6.23 – both with the same latency as Moshi. The leading back-to-back system, Unmute (also supported by gpt-4.1), scored 7.70, but with an average latency of 2.1 seconds versus near zero for KAME.
To isolate background power from timing effects, the research team also evaluated background LLM script responses from the final oracle injection directly into each KAME session – bypassing the early generation problem altogether. These scores averaged 7.79 (reasoning 6.48, STEM 8.34, humanities 8.56), compared to Unmute’s 7.70. This confirms that the KAME gap in sequential systems is not a ceiling on LLM background knowledge, but is a consequence of starting to speak before hearing the user’s complete query.
Most importantly, KAME is complete Atheist background. The front-end was trained using gpt-4.1-nano as the primary back-end, but switching in claude-opus-4-1 or Gemini-2.5-flash at inference time required no retraining. In Sakana AI experiments, claude-opus-4-1 tended to outperform gpt-4.1 on inference tasks, while gpt-4.1 scored higher on humanities questions – suggesting that practitioners can route queries to MBAs best suited to the task without touching the front-end model.
Key takeaways
- KAME bridges the gap between speed and knowledge in conversational AI By running the front-end speech-to-speech model and the back-end LLM model asynchronously in parallel – the S2S model responds instantly while the LLM continually injects progressively refined “oracle” signals in real time, shifting the model from “think, then speak” to “speak while thinking.”
- Significant performance gains without any latency cost – KAME raises the MT-Bench score from 2.05 (Moshi baseline) to 6.43, approaching the Unmute’s 7.70, while maintaining a near-zero average response time versus the Unmute’s 2.1 seconds.
- Architecture is completely background agnostic – The front end was trained using gpt-4.1-nano but supports plug-and-play switching of any parametric LLM (gpt-4.1, claude-opus-4-1, gemini-2.5-flash) at inference time without retraining, allowing task-specific LLM selection based on domain strengths.
verify Model weights, paper, inference code and Technical details. Also, feel free to follow us on twitter Don’t forget to join us 130k+ ml SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us


