The race to make large language models faster and cheaper to run has been fought largely at two levels: model architecture and hardware. But there is a third, often underappreciated frontier: the graphics processing unit (GPU) core. A kernel is a low-level computational routine that actually performs a mathematical operation on the GPU. Writing a good one requires understanding not only the mathematics, but also the precise memory layout, instruction scheduling, and hardware quirks of the chip you’re targeting. Most machine learning professionals don’t write kernels directly; They rely on libraries like FlashAttention or Triton to do it for them.
meet No problem: QwenLM’s contribution to this layer. It is released under the MIT License and is built on the TileLang compiler framework, a high-performance linear attention kernel library specifically optimized for the Gated Delta Network (GDN) attention mechanism – the linear attention architecture that powers the Qwen3.5 and Qwen3.6 model families.
What is linear interest and why is it important?
To understand what FlashQLA solves, it is useful to understand what standard softmax attention costs are. In a traditional transformer, the attention mechanism has a complexity of O(n²), which means that doubling the length of the sequence quadruples the computation. This is the primary bottleneck that makes processing long documents, long code files, or long conversations expensive.

Linear attention replaces softmax with a formula that reduces this to a complexity of O(n), making it a much better measure with sequence length. Gated Delta Network (GDN) is one of the linear attention mechanisms, and has been integrated into the hybrid Qwen model architecture, where GDN layers alternate with standard full attention layers. This hybrid design attempts to get the best of both worlds: full attention expression where it’s needed most, and linear attention efficiency everywhere else.
GDN uses what is called a “gated” formulation – it applies a heavily decomposed gate to control the amount of previous context that is carried forward. This gateway is the key to how FlashQLA achieves performance gains.
The problem is with the existing kernel
Before FlashQLA, the standard implementation of GDN operations came from the Flash Linear Attention (FLA) library, which uses the Triton kernel – Triton is OpenAI’s Python-based GPU programming language. While Triton makes kernel authoring easier, it comes with trade-offs: the kernels it produces are not always optimally scheduled for specific hardware, especially in NVIDIA’s Hopper architecture (H100 and H200 GPU generation).
The Hopper architecture introduced new features such as warpgroup-level Tensor Core operations and asynchronous data pipelines that Triton could not always exploit to its full potential. This is the gap that FlashQLA is designed to fill.
What FlashQLA does differently
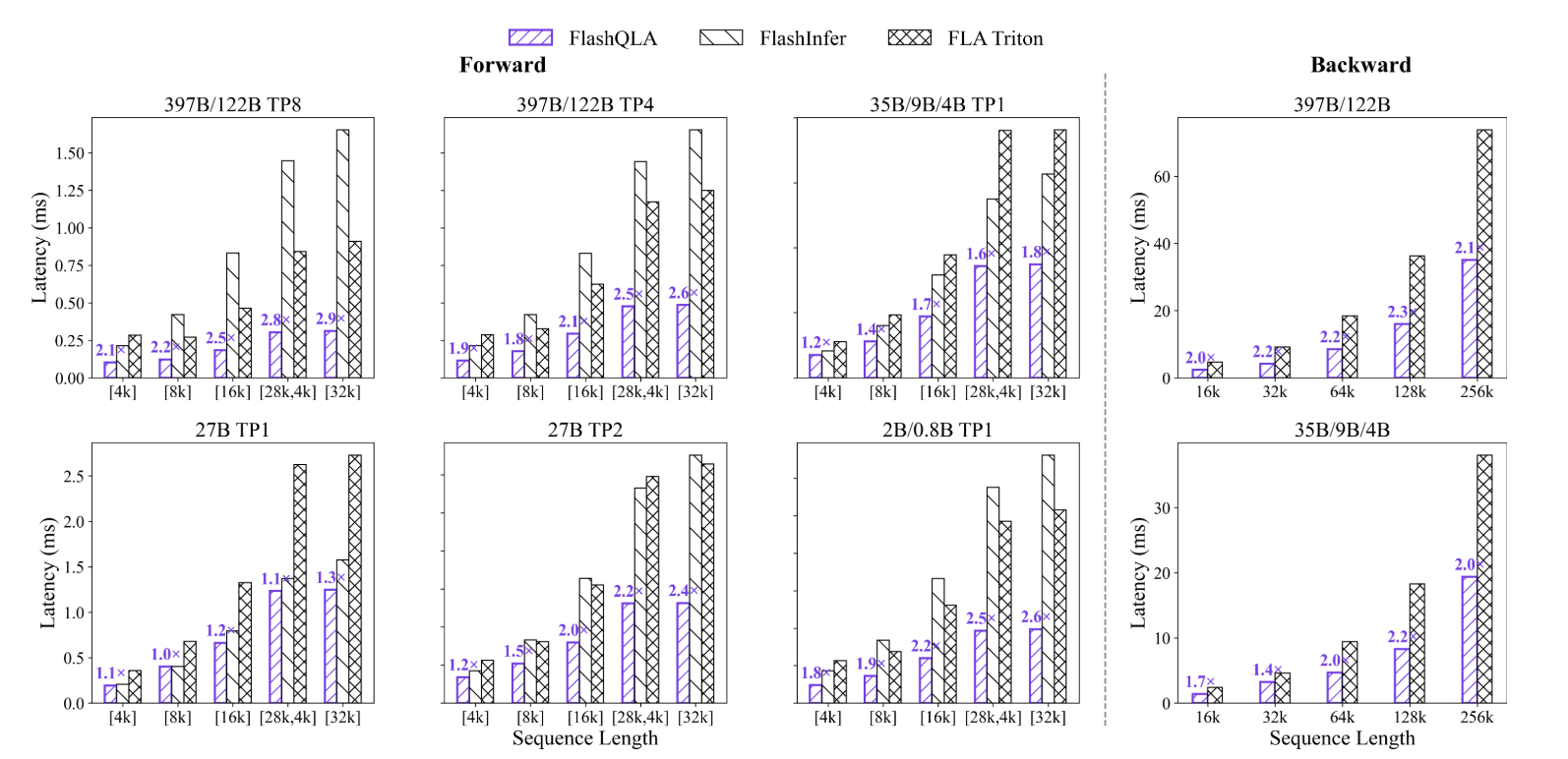
FlashQLA applies operator fusion and performance optimization to both the forward pass (used during inference and training) and backward pass (used during training to calculate the gradient) of the GDN Chunked Prefill. The result is A 2-3× acceleration of forward passes And a 2 x Acceleration of back passes Compared to FLA Triton core across multiple scenarios on NVIDIA Hopper GPUs.
Three technical innovations are driving these gains:
1. Automatic gateway-driven intra-card context parallelizationContext parallelism (CP) refers to splitting a long sequence across multiple processing units so that they can work on different parts simultaneously. FlashQLA exploits the exponential decay property of the GDN gateway to make this dichotomy mathematically correct – because gate decay means that tokens farther apart in the sequence have a decreasing influence on each other. This allows FlashQLA to automatically enable in-card CP under tensor parallelism (TP), long serialization, and small head count settings, optimizing utilization of the GPU stream multiprocessor (SM) without requiring manual configuration.
2. Hardware-friendly algebraic reformulationFlashQLA reworks, to some extent, the mathematical computation of the forward and backward flows of the GDN Chunked Prefill to reduce the load on three types of GPU hardware units: Tensor Cores (which handle matrix multiplications), CUDA Cores (which handle scalar and vector operations), and the Special Function Unit (SFU, which handles operations like exponents and square roots). Importantly, this is done without sacrificing numerical accuracy, which is an important guarantee when using reformulations for model training.
3. TileLang fused specialized warp beads: Instead of decomposing computation into independent sequential kernels (too slow) or consolidating everything into a single monolithic kernel (too hard to optimize), FlashQLA takes a middle path. TileLang is used to build multiple embedded cores and manually implement warpgroup specialization – a technique that assigns different warpgroups (groups of 128 threads on Hopper) to specialized roles, such as one warpgroup moving data from global memory to shared memory while another warpgroup simultaneously runs Tensor Core matrix multipliers. This overlap between data movement, Tensor Core computation, and CUDA Core computation is what allows FlashQLA to approach the theoretical maximum hardware throughput.
Standards
FlashQLA was benchmarked against two baselines: FLA Triton kernel (v. 0.5.0, Triton 3.5.1) and FlashInfer (v. 0.6.9), using TileLang 0.1.8, on NVIDIA H200 GPUs. The benchmarks used head configurations from the Qwen3.5 and Qwen3.6 model families, with head dimensions hagainst ∈ 64, 48, 32, 24, 16, 8, corresponding to the tensor parallelism settings TP1 to TP8.
FWD benchmarks measure the latency of a single core for different models and TP settings within different batch lengths. BWD examines the relationship between the total number of tokens within a batch and the response time during a single update step.
Key takeaways
- FlashQLA is a high-performance linear attention kernel library Created by the Qwen team at TileLang, it is specifically optimized for Gated Delta Network (GDN) split forward and backward passes.
- It achieves 2-3× forward acceleration and 2× backward acceleration Crossed the FLA Triton core across multiple scenarios on NVIDIA Hopper (SM90+) GPUs, with more pronounced efficiency gains in pre-training and edge-side proxy inference.
- Three key innovations drive performance gains: Automated gate-based in-card context parallelization, hardware-friendly algebraic reformulation that minimizes Tensor Core, CUDA Core, and SFU without loss of digital precision, TileLang merges specialized kernels in convolution that overlap data movement, Tensor Core computation, and CUDA Core computation.
- GDN is a linear attention mechanism with O(n) complexity.used in Qwen’s hybrid model architecture alongside standard full attention layers – making efficient GDN kernels essential for both training and large-scale long-context inference.
- FlashQLA is open source under the MIT License It requires SM90 or higher, CUDA 12.8+, and PyTorch 2.8+, with simple pip installation and high-level and low-level Python APIs available for integration.
verify GitHub repo and Technical details. Also, feel free to follow us on twitter And don’t forget to join us 130k+ ml SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us