
Understanding what’s happening in an audio clip is a deceptively difficult problem. Transcribing pronunciations is the easy part. A truly capable system would also need to recognize the speaker, detect their emotional state, interpret background sounds, analyze musical content, and answer time-related questions such as “What did the speaker say at the two-minute mark?” Addressing all of this requires integrating multiple specialized systems together.
Launched by the team of OpenMOSS, MOSI.AI and Shanghai Innovation Institute mos-sound: An open source phonemic understanding model designed to unify all these capabilities within one basic model.
What MOSS-Audio actually does
Supports MOSS-audio Speech understanding, environmental sound understanding, music understanding, voiceover, time-sensitive quality assurance, and complex reasoning Voice over in the real world. Its set of capabilities is divided into several distinct areas. Understanding speech and content Accurately recognizes and records spoken content, and supports alignment of word-level and sentence-level timestamps. Speaker, emotion and event analysis It identifies speaker characteristics, analyzes emotional states based on tone, timbre, and context, and detects key acoustic events within a voice. Scene and audio signal extraction It pulls meaningful cues from background sounds, environmental noise, and non-speech cues to infer scene context and atmosphere. Understanding music Analyzes musical style, emotional progression, and instrumentation. Answer and summarize audio questions Handles questions and summaries across speech, podcasts, meetings and interviews. finally, Complex logic Performs multiple-hop reasoning on audio content, supported by both thought-sequencing training and reinforcement learning.

In practice, a single MOSS-Audio model can do all of the above without switching between different specialized systems.
Four different models
The team released four variants at launch: MOSS-Audio-4B-Instruct, MOSS-Sound-4B-Thinking, MOSS-Audio-8B-Instructand moss-sound-8b-thinking. The naming convention is worth understanding if you decide to use it. the guidance Variables are optimized to follow direct instructions, making them well-suited for production lines where you want organized, predictable output. the Thinking Variables provide stronger train-of-thought inference capabilities, and are better suited for tasks that require multi-hop inference. 4B models are used Quinn 3-4b As the backbone of the LLM, use Forms 8B Quinn 3-8bresulting in total model sizes of approximately 4.6B and 8.6B parameters, respectively.
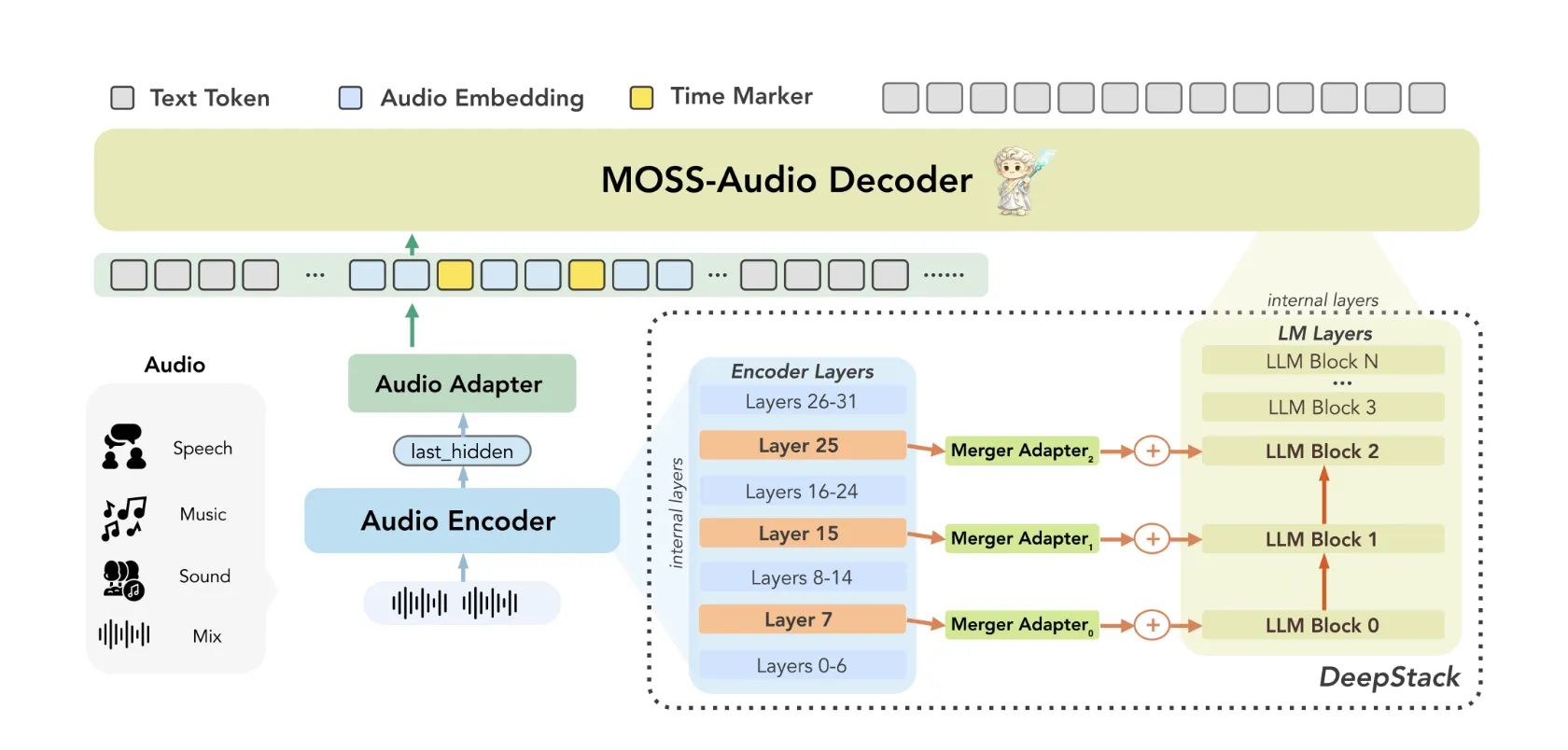
Architecture: Three components working together
MOSS-Audio follows a A modular design consisting of three components: an audio encoder, a pattern converter, and a large language model. Raw audio is first encoded by a file MOSS-vocal encryption To continuous time representations in 12.5 Hz. These representations are then projected into the language model embedding space through the transformer, and finally consumed by LLM to generate autoregressive text.
The research team trained the encoder from scratch instead of relying on ready-made voice interfaces. Their reasoning: A custom encoder provides more robust speech representations, tighter temporal alignment, and better scalability across phonetic domains.
There are two architectural innovations within MOSS-Audio that are worth understanding in detail.
Inject DeepStack features across layers: A common weakness of acoustic models is that relying solely on the upper-layer features of the encoder results in the loss of low-level acoustic information, things like prosody, transient events, and local time-frequency structure. MOSS-Audio handles this through a file deepstack-Inspired cross-layer injection module between the encoder and the language model: In addition to the encoder’s final layer output, features from the previous and intermediate layers are selected, displayed independently, and injected into the early layers of the language model. This preserves multi-detailed information ranging from low-level phonetic details to high-level semantic abstractions, helping the model retain rhythm, timbre, transients, and background structure that a single high-level representation cannot fully capture.
Perceptual representation of time: Time is a crucial dimension of audio that textual models are not equipped to handle naturally. MOSS-Audio handles this through a file Insert time marker Strategy during pretraining: Explicit temporal codes are inserted between representations of audio frames at specific intervals to indicate temporal positions. This allows the model to know “what happened when” within a unified text generation framework, naturally supporting ASR timestamp, event localization, time-based quality assurance, and long audio retrieval – without the need for a separate translation head or post-processing pipeline.
Standard performance
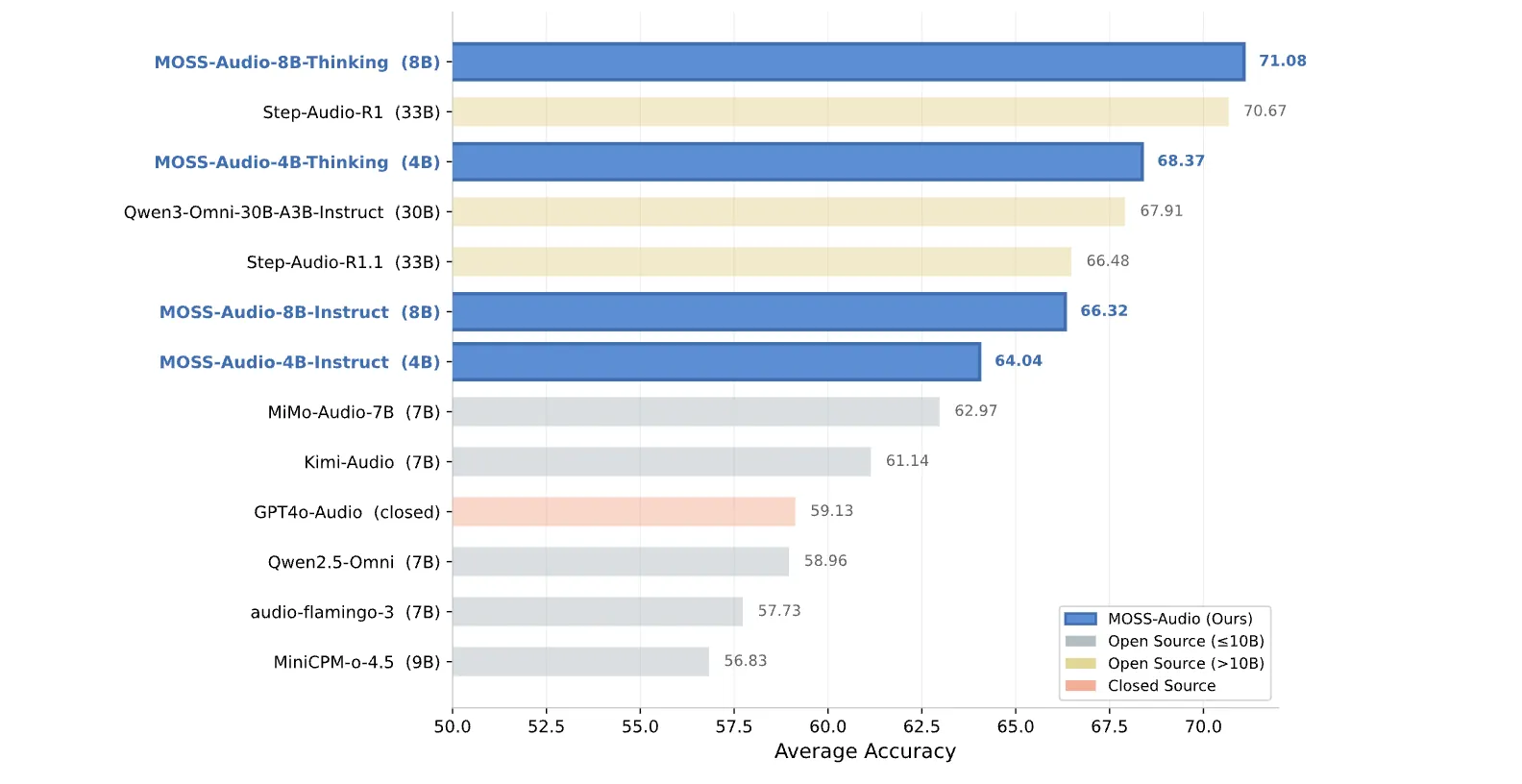
The numbers are strong. In understanding the overall voice, MOSS-Audio-8B-Thinking achieves an average accuracy of 71.08 Across four criteria – 77.33 on MMAU, 64.92 on MMAU-Pro, 66.53 on MARand 75.52 on MMSUoutperforming the majority of open source models. This includes larger models: the Step-Audio-R1 at 33B scores 70.67, and the Qwen3-Omni-30B-A3B-Instruct at 30B scores 67.91. For more context, the Kimi-Audio (7B) scored 61.14 and the MiMo-Audio-7B scored 62.97 on the same average. The 4B Thinking variant received a score of 68.37, meaning that the smaller model with thought-sequencing training outperformed all of its larger, instruction-only competitors.
on Explain the speechassessed using the LLM-as-a-Judge methodology across 13 micro-dimensions including gender, age, accent, pitch, volume, speed, texture, clarity, fluency, emotion, tone, personality, and summary, lead the MOSS-Audio-Instruct variables across 11 out of 13 dimensions, with MOSS-Audio-8B-Instruct achieving the best overall average score 3.7252.
on Automatic Speech Recognition (ASR) Includes 12 dimensions to evaluate – including health status, code-switching, accent, vocalization, and non-speech scenarios – MOSS-Audio-8B-Instruct The lowest overall character error rate (CER) is 11.30 In all models tested.
Key takeaways
- One model, full audio stack: MOSS-Audio unifies speech transcription, speaker and emotion analysis, environmental sound understanding, music analysis, voiceover, time-aware quality assurance, and complex reasoning into a single open source model, eliminating the need to tie together multiple specialized systems.
- Two architectural innovations drive performance: DeepStack Cross-Layer Feature Injection preserves multi-detailed audio information by injecting features from the intermediate coding layers directly into the early layers of the LLM, while the inclusion of a time tag during pre-training gives the model explicit temporal awareness for timestamp-based tasks.
- Best-in-class benchmark results on an efficient scale: MOSS-Audio-8B-Thinking achieves an average accuracy of 71.08 on general audio comprehension benchmarks, outperforming all open source models including the 30B+ systems, while the 4B Thinking variant alone outperforms every larger open source education-only competitor.
- Dominant ASR timestamp resolution: The MOSS-Audio-8B-Instruct scored 35.77 AAS on the AISHELL-1 and 131.61 AAS on LibriSpeech, significantly outperforming both the closed-source Qwen3-Omni-30B-A3B-Instruct (833.66) and Gemini-3.1-Pro (708.24) on the same benchmark.
verify Typical weights and Repo. Also, feel free to follow us on twitter And don’t forget to join us 130k+ ml SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Do you need to partner with us to promote your GitHub Repo page, face hug page, product release, webinar, etc.? Contact us

